Strange Loop 2019 - ¡Escuincla babosa! A Python Deep Learning Telenovela
Overview
Telenovelas are beloved for their over the top drama and intricate plot twists. In this talk, we'll review popular telenovelas to synthesize a typical telenovela arc and use it to train a deep learning model. What would a telenovela script look like as imagined by a neural network? To answer this question, we'll examine three Python deep learning frameworks - Keras, PyTorch, and TensorFlow - to determine the process of translating a telenovela into a neural network and ultimately determine which one will be best for the task at hand. Be prepared for amor, pasiòn, and y el misterioso!
Preface
Lorena Mesa loves Telenovelas. The idea for this talk came about because she's a data engineer, but not a machine learning engineer. She wanted to explore the ML world, so she decided to combine it with things she loved.
Initially she took us through some examples of places in the world around us where we see deep learning in particular in use. One example was DeepGlint, which uses deep learning to drive insights into the behavior of things like people and cars. She showed an example of DeepGlint running on a video of people in a bank, where we could see it tracking the objects and their rotation. She also discussed deep learning's utility in registering both faces and license plates on cars and motorcycles in traffic scenes.
Another place example of deep learning in the world that she discussed was realtime translation, as with Google doing live translations on your phone. Google takes an image, translates to text, does its thing, then translates it back.
Finally, Mesa touched on deepfakes, showing us a video of Stennifer Laurence 7, a mashup of Jennifer Lawrence and Steve Buscemi. She talked about how we're seeing is that this kind of technology can shift our conception of what is true and what true even means.
After looking into these things, Mesa became interested in another place where deep learning has been having an effect; social media. She showed an example of Keaton Patti having a bot 'watch' 1000 hours of Saw movies, then try to write a script, which in turn inspired her to consider what deep learning could do with telenovelas.
When people start talking about what's possible with deep learning, Mesa said we get into subtler definitions of what it means to be creative and to model creativity in the world. She then showed another ars technica piece about a StrangeLoop alumni who had an AI generate a David Hasselhoff script, and then turned it a short film. This was all to show that deep learning is everywhere, being used to do everything from understand traffic to make art.
So why Telenovelas?

First off, Mesa asks, why not? One her favorites is called Maria la del Barrio, and there's this scene that's perhaps more absurd than the auto-generated Hasselhoff script, but people wrote this one. The basic premise is that our main villain, Soraya Montenegro, is having a party where Nandito, her ex's son, slips into his stepsister's room to tell her he loves her. As they're having this moment where they're about to kiss, Soraya walks in and screams "Escuincla babosa!"" which roughly means 'you stupid spoiled entitled brat!' The next few minutes are a huge mess, in which a very dramatic fight takes place where Soraya basically fights everyone, including a random man in a suit whose presence is not even explained. Mesa's thinking was if people can generate this delightful absurdity on their own, machine learning really has something to contribute there.
Thinking about what it means to generate a telenovela with deep learning, Mesa says we have to ask ourselves what a telenovela is.
"The social phenomenon of televised melodramas, called telenovelas in Spanish … are serial melodramas … [based] on the construction of a relationship of fidelity with the audience"
- Jorge Gonzalez, 2003, Understanding Telenovelas as a Cultural Front
These serial melodramas are beloved worldwide, watched in more than 100 countries, cost about $800 million a year to make, and about 1/3 of the world population (2 billion people) watch them. So what is the arc of a telenovela that compels people so much? One factor is, in the words of Dr. Diana Ross:
"Things have to be cleaned up so the audience has satisfaction. They won't worry about Maria - did she find true love, her true mother or her true father?”"
Telenovelas depend on 3 social processes:
- Building symbolic commonalities between the social agents and cultures
- Creating a believable set of worlds
- Enacting symbolic struggles that define basic human cultural elements in these worlds
When we think about the struggles of a telenovela, they are used to prolong the inevitable conclusion, pulling at people's heartstrings to keep watching right until the very end. This only works, though, because we know the happy ending is eventually coming.
So for the arc of the telenovela, unlike an english soap opera, we need to create these three things:
- a fixed melodramatic plot
- a finite beginning and ending
- a conclusion that ties up all thee loose ends
Soap operas, meanwhile, never end.
So what's the formula to build the telenovela?
Mesa looked at 3 major famous telenovelas; La Reina del Sur, Yo Soy Betty, La Fea, and Juana la Virgen. They are all major productions, widely distributed, high budget and, key point, they each have english version - Queen of The South, Ugly Betty, and Jane The Virgin. They all fit the arc requirements she was looking for perfectly.
So then she got into how to use deep learning for text generation. She brought up the following definition of what machine learning actually is:
"A computer program is said to said to learn from experience (E) with respect to some task (T) and some performance measure (P), if its performance on T, as measured by P, improves with experience E." - Tom Mitchell , Machine Learning (1997)
She showed us the below graph of the machine learning landscape:
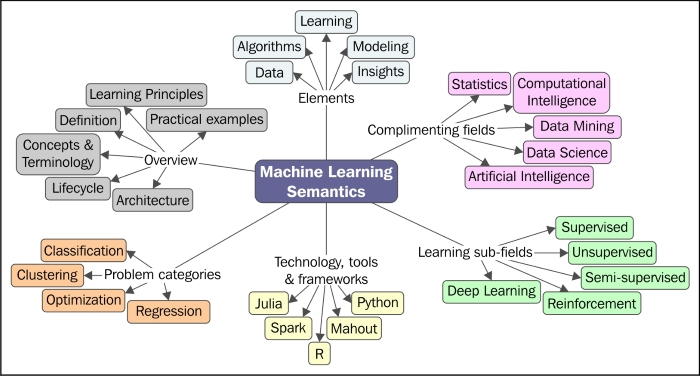
and noted that deep learning is solidly in the research area. Then she discussed the main differences between supervised and unsupervised learning. Unsupervised learning, what she used, implies that we don't know what the outputs of our machine learning algorithm will look like ahead of time, as the algorithm will determine them itself.
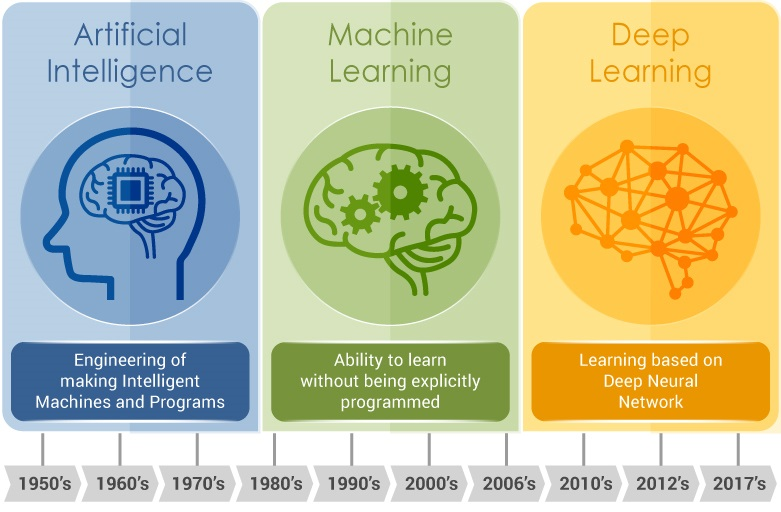
She showed us this timeline of the evolution of thought in the AI world, and how it's built towards the deep learning, self-directed approach she's exploring with this project. She emphasized the value of algorithms that can evaluate and build meaning about the world that we didn't explicitly program into them.
Then, she got into some of the details about what neural nets and deep learning are. She displayed this diagram of a neural network:
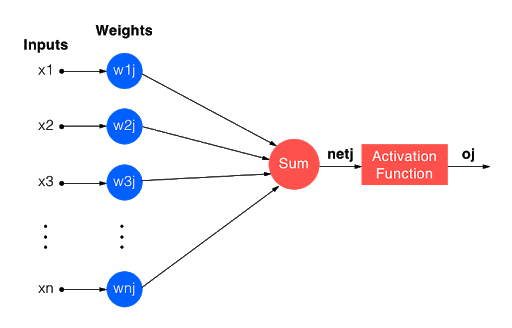
and defined the following 3 terms.
Inputs - features represented as some weighted number. Weights - the numeric value indicating the strength of the feature. Generally the higher the number, the more significant that input is. Outputs - weighted sum of inputs passed through the activation function (non-linear function)
In training our network, Mesa says, we're basically just iteratively adjusting the weights. Our activation function mimics the behavior of an actual neuron's firing rate.
She then moved into discussing the GP2 algorithm, which was used to generate text for Stennifer, the deepfake mentioned earlier in the talk. It required minimal input to produce text that people actually had trouble determining whether it was human-generated or not. So that seemed perfect for the telenovala!
There are two models available for deep learning text generation; character and word models. There are also many different architectures she could have used for her neural net, but she went with an LSTM RNN because they're good at processing data in sequence and can use the output data as input, allowing it to fine-tune its insights. She looked at 3 different implementations for creating an RNN in python as well, specifically Keras, TensorFlow, and PyTorch.
Considering questions such as how much expertise each option requires and the size of her datasets, she decided that TensorFlow was the best option. It's easy to set up and debug, has both high and low-level APIs, and even allows you to use the simpler Keras API in versions 2.0 and above, while having more optimizations available than vanilla Keras. TensorFlow also allows you to use eager execution, which runs your code sequentially and is therefore slower but much easier to debug.
The next step in the process is transferring your input test into vectors with a hot encoding, where you tokenize your words or characters, feed it to your model, and then train for N epochs.
Mesa says that you want to be reducing your loss each time you train. You can then export the weights associated with your training to find your optimal loss value. Then you build your model and drop in your ideal weight file that you've derived from running through so many epochs. And you're done! Mesa says that you can build a model using Keras to apply LSTM and compile and train it fairly easily, and encourages people to play around with it.
Results!
Mesa optimized her model for 100 character outputs, and 30 epochs seemed to produce good results. Some of the outputs of her telenovala model that Mesa shared are below:
Text Generated: (30 epochs - Jane the Virgin - 5 SEASONS = 100 EPISODES)
"is it a milagro? was i drinking? no. no. my god, no! i wasn't. what made you ask that i am still me"
Text Generated: (30 epochs - Ugly Betty - 4 SEASONS - 85 EPISODES)
"the graphics department is very unhappy. do not pull or bite their hair ahem let’s show softer side"
Text Generated: (30 epochs - Queen of the South - 4 SEASONS - 52 EPISODES)
"do not threaten me. do you understand me? do you understand me? whoa, whoa, all right? hey, look, i"
Text Generated: (30 epochs - All)
"i’m proof that surprise happen. even if you do not believe me. why would you? i am a woman after all"
They're pretty good (particularly that last one), but Mesa asks what we could do to improve things further? Her first thought is to train individual models for each character and let let them interact, creating more interesting interactions. Another idea would be to expand her training dataset, finding similar enough inputs to her core example that they could still teach the model something. Finally, she could train models to specialize in specific plot arcs, such as lost love, amnesia, etc.
Her final take away is that text generation is hard, and though small snippets of it work well, without coherent narratives and consistent characters, ML model-generated telenovalas won't quite hit the mark.
Finally, there wasn't a pre-existing dataset for this! Mesa generated hers herself, and would love help expanding it here: github.com/lorenanicole/ telenovela_scripts