A dev's thoughts on developer productivity
Why don't we hear more developer voices in the conversation about "developer productivity"? Most self-styled experts on developer productivity seem more interested in selling something rather than painting an accurate picture of how devs really work. Perhaps as a consequence, we're swimming in acronyms, magic metrics, and methodologies, but not a lot of rigorous systems thinking.
Devs are systems thinkers. Our job is to model and build systems, and we often draw out diagrams and schematics to illustrate how those systems work. But when it comes to our own work, we are letting others draw the pictures—and they've done a poor job. I doubt that I'm the only dev who feels a little wary of what the "experts" on my productivity have had to say.
Instead, shouldn't we start from direct experience, our own mental models of how we work? Shouldn't we be drawing pictures and diagrams that actually approximate the world in which we live? Here's an attempt to do so.
Picture 1: The inner loop and outer loop
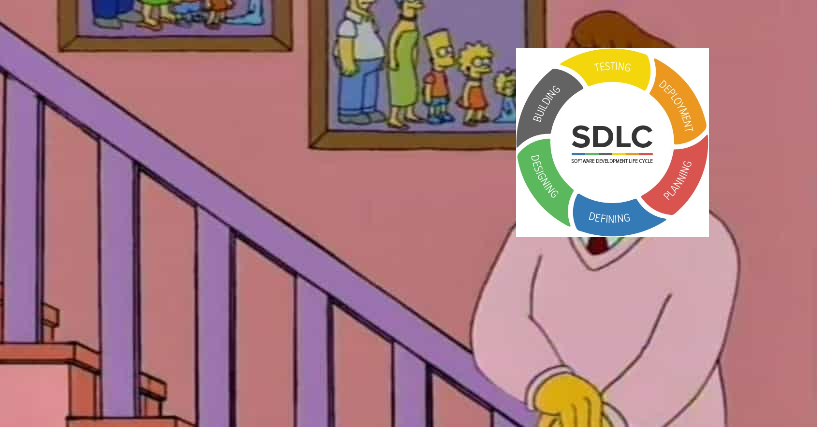
The common picture of the software development process is the SDLC. A mainstay of DevOps marketing campaigns, the SDLC does a good job of highlighting the many stages involved in bringing code to production. The SDLC, however, leaves the most critical step in software development undefined: how the code, itself, is understood and written.
When I think of my own work as a developer, there isn't just one big loop, as pictured in the SDLC, but two nested loops:
- The outer loop maps roughly to the SDLC and happens at the level of sprints, projects, or releases.
- The inner one is the read-write-run loop that happens many times per day when you're in the thick of understanding code, writing code, running tests, and repeating until you're happy with the code.

You enter the inner loop whenever you get "close to the source" in the development process. This happens at multiple points in the outer loop, such as when you’re:
- Onboarding to the code you're about to change.
- Authoring a new feature or bug fix.
- Fixing a test that broke in CI.
- Reviewing a patch or responding to a review.
- Debugging what went wrong in a failed deployment.
- Remediating an incident in production.
It's important to talk about the inner loop. It's the heart of software creation. If you don't talk about it, then your organization will treat it as if it doesn't matter.
Picture 2: Reaching flow state
Inside the inner loop is the golden state: Flow. Flow state is that state of focus and productivity that you attain when you're feeling inspired and motivated. It’s when you have "paged in" all the necessary context and can actually have fun. It's when you're coding at the speed of thought. The ideal path to Flow is represented in this first graph:

Reaching flow state accelerates the inner loop. But flow state takes uninterrupted time to reach. Mental context switches take you out of it. The most common complaint I hear from developers struggling to get things done is that there are too many interruptions. Many devs' day-to-day sadly looks more like this graph:

Flow-destroying interruptions can be internal or external.
- An external context switch is triggered by an external factor, like a scheduled meeting or an impromptu question from a teammate.
- An internal context switch is triggered by a necessary side quest, such as the need to understand how to use a library, the need to set up a tool, or the need to resolve a blocking issue.
I suspect that every programmer has experienced the 1st graph at some point in their lives, probably early enough to suck them into programming—that feeling of flow can be quite the gateway drug. But many get stuck in the second graph when they code professionally, and that is a great source of developer misery and lost productivity.
A unit for developer productivity
The above charts reveal a question we should ponder before proceeding: What exactly is "productivity", the y-axis in our chart above? Many developers can describe how it feels, but can we arrive at a more precise definition? Lines of code? Number of commits? Some synthetic metric derived from version control history? All these seem like poor measures of developer productivity.
Software development is at its core an innovative endeavor. Unlike the manufacture of physical things, the goal is not to produce something that has been produced before. The goal is to produce new and useful knowledge. The atomic unit of innovation is iteration—the cycling of the inner loop.
The atomic unit of developer productivity ought then to be one iteration of the inner loop. The appropriate unit is not code quantity, but iteration frequency. We might call this unit of quantity developer hertz.
Picture 3: Progress is a vector sum in codespace
In the physical world, velocity has two components: direction and speed. Analogously, developer velocity can also be broken down into a direction and a magnitude.

The speed component indicates how quickly you're cycling through the inner loop. The more you reach flow state, the faster you iterate, and the sooner you’re able to ship your new feature or patch.
The directional component reflects the technical direction taken—whether you use library X or Y, for example. Picking a good direction might provide a critical shortcut. Picking a bad direction might mean you have to retrace your steps later.
Great direction-setting means making the choices that get an end-to-end system up and running as quickly as possible. Getting an end-to-end system up quickly de-risks the overall project. Reaching a shippable state well before the appointed deadline means you can make further improvements in the time remaining. It's helpful to view the destination not as a single point, but as a zone of acceptable outcomes. Get into the acceptable zone first and then improve your position.
Picture 4: Team velocity is the low-variance sum of high-variance individuals
So far, our pictures have treated software development as a solo endeavor. But most software is made in teams. Teamwork leads to more robust and consistent progress. As the old adage says, "If you want to go fast, go alone. If you want to go far, go together."
Individual velocity tends to be choppy. There are inevitably days spent mostly onboarding to unfamiliar code or where external factors interrupt regularly scheduled programming. But individual bumps smooth out when you add them together.

If a team suffers from a sustained period of low productivity, it's worthwhile to ask what factor caused a correlated drop in productivity across all members of the team. Sometimes, there's a natural explanation—perhaps a new quarterly planning process took up an inordinate amount of time. And sometimes there is a more serious cause—morale issues, technical debt, or a lack of clear goals and priorities.
Picture 5: Concurrency is not parallelism
It's generally believed that the productivity of a software team scales sub-linearly—and eventually decreases—with the size of the team. There are analogs here to parallel computing and Amdahl's law. If you double the number of CPUs on a machine, programs may get faster, but almost never twice as fast.
In computers, the factors that slow down parallelization are CPU context switching and how work is broken into independently processable chunks. In software teams, the primary factors are communication overhead, the dependency structure of the work, domain expertise, and the speed of context acquisition.
You can draw this out in a picture where you've broken down a project into different deliverables. The finished product is a pyramid of sorts, where the blocks at the bottom have to be laid before the ones on top:

The colors map to different areas of domain expertise. If you are a developer with expertise in multiple areas, you could build the entire project yourself. Or you could delegate the task to two other developers who each have expertise in a single area:

The two developers have the advantage that they can build separate blocks in parallel, but their parallelism is constrained by serial dependencies (some blocks must be laid before others), the friction of onboarding to unfamiliar parts of the code, and communication overhead.
It is wishful thinking that the project will be completed twice as fast by two developers as by one. Indeed, even net speedup is no guarantee. But some amount of net speedup is well within reach if there is good division of labor and team rapport.
Each added person, however, increases the complexity of the coordination task and most teams see vastly diminishing returns with each additional person. This is why many organizations prioritize hiring and retaining the best developers over just expanding the size of the team. They also invest in tooling that enables greater individual productivity and helps with the coordination of software development at scale.
If we don't talk about developer productivity, someone else will
Earlier, I said that if developers didn't talk about these elements of our productivity, then our organizations wouldn't realize they matter.
Even worse, however, is someone else coming along and convincing our organizations that other things matter more. Too often, we find ourselves crammed into a framework that views software creation not as a journey of discovery, but as an unimaginative widget factory. Rather than value the inner loop, where all code is understood and created, we're asked to think only in terms of the mechanical outer loop. What good is "change failure rate" if you can't even jump-to-def across your code? Rather than invest in quality tools that improve our lives as engineers, we're compelled toward the classic Mythical Man Month fallacy that leads to more people, more code, and more problems.
It is to our benefit, and to the benefit of our industry and society at large, to advance mental models that reflect the reality of our work and honor its essential creativity.
In this post, I've sketched out some pictures that resonate with one developer—me. What about you? When you think about your own creative process and that of your team, what pictures do you see?
Huge thanks to Dan Robinson, Thorsten Ball, Stephen Gutekanst, Timothy Liu, and Nick Moore for providing feedback on this post.
About the author
Beyang Liu is the CTO and co-founder of Sourcegraph. Beyang studied Computer Science at Stanford, where he published research in probabilistic graphical models and computer vision at the Stanford AI Lab. You can chat with Beyang on Twitter @beyang or our community Discord.