Strange Loop 2019 - Temporal Databases for Streaming Architectures
Overview
Time is intrinsic to information and yet it is usually an afterthought in database designs. We present Crux, a general purpose open source document database with bitemporal graph queries. This talk will explore the journey of how Crux was conceived from JUXT's consulting experiences of building global system integrations and providing temporal query capabilities for financial services projects.
Presenters: Jon Pither and Jeremy Taylor are from the UK. They love Clojure & open source technology.
How do we handle time in a streaming architecture?
This talk aims to share the lessons JUXT learned about handling time in streaming architectures and building Crux.
The basis for this talk is event streaming and the unbundled database as described in Martin Klepmann's talk on "Turning the Database Inside Out".
Event streaming promises simplicity through a decoupled architecture and the possibility for lightweight components that perform their specific functions very well.
Event streaming (in the context of Kafka & its community) basically says, once you've put all your canonical information in Kafka, everything else, including your applications are just materialized views on the streams held by Kafka. Streams are the central nervous system for your organisation.
The log is not enough
Streams of events flow through the logs and what we often want to do is look at a timeline and see how those events come together. Time is the factor that brings in this meaning.
The log is just storage - an append-only sequence of records. The record ingestion time in the log is not necessarily the same thing as the event time, so how would you use a log to interpret the actual order of events?
Jon and Jeremy also talk about how logs by themselves do not make it easy to invalidate or delete events. This brings us to bitemporality.
Bitemporality
Put simply, bitemporality is about separating the time when an event occurs and when the occurrence of the event is known.
When you're using logs, events come in but you cannot make sense of their order (since only the time of ingestion is reported). So now, it's easy to think, fine, but then bitemporality is just two timestamps right? What is the big deal about implementing that?
Let's define some terms before we counter that.
Transaction time: when a fact is transacted, or more simply when a transaction occurs. Valid time: when a fact is said to be true.
Example: You have a big enterprise with offices all over the world and at each office, several trades are executed at different points in time. The enterprise is spread across different timezones as well. As of any one point in time, you can't see all the events that happened then because you didn't capture TransactionTime in the system, even if you know that the event happened. This is why ValidTime is more useful. ValidTime is more forgiving & fungible. It adds business character that TransactionTime doesn't. A consistent view of the timeline around a certain event must combine ValidTime and TransactionTime.
Bitemporal modeling is not a new concept. It's been around for decades as a concept useful in heavily regulated industries like insurance and finance companies among others. To deal with these regulations, sometimes these columns have to be handcrafted and accommodated in relational databases that already exist. Implementing bitemporal queries is still difficult because it's a niche concept and operationally complex. Bitemporality is an open problem.
How do we handle time in a streaming architecture?
In streaming architectures, it's very common to have multiple event streams. To work with them, we have to
- consume them
- aggregate some or all of them
- lastly, produce another event or expose an API
Let's look at two possible approaches for handling such architectures. The first one is monolithic databases. Basically use existing databases like Postgres. There may already be a lot of tooling for these available which is a plus. The downside is the the cost, and no one-size-fits-all solution is usually possible. Additionally, using relational databases in this way can lead to a proliferation of ad-hoc event ordering. As you try to shoehorn bitemporality as a feature into these existing systems you can end up with more monoliths as you find out that you need more features that you can't provide, like adding in ElasticSearch to support certain types of searches.
Another approach is using existing stream processing tools (Flink, Samza, Druid, Storm, etc). They're already built for throughput, have native support for event ordering and unlimited windowing. The downside is that there is no way to know how big your window should be. Performance may not be optimal for unlimited windowing. It's still like your window is sitting on a firehose of data, which is basically meaningless as it's not a "window" if you aren't restricting it. Ultimately, there's a lack of bitemporal awareness.
So what do Jon and Jeremy suggest? A custom temporal view with full control.
They discuss a case study which is similar to the enterprise example described above.
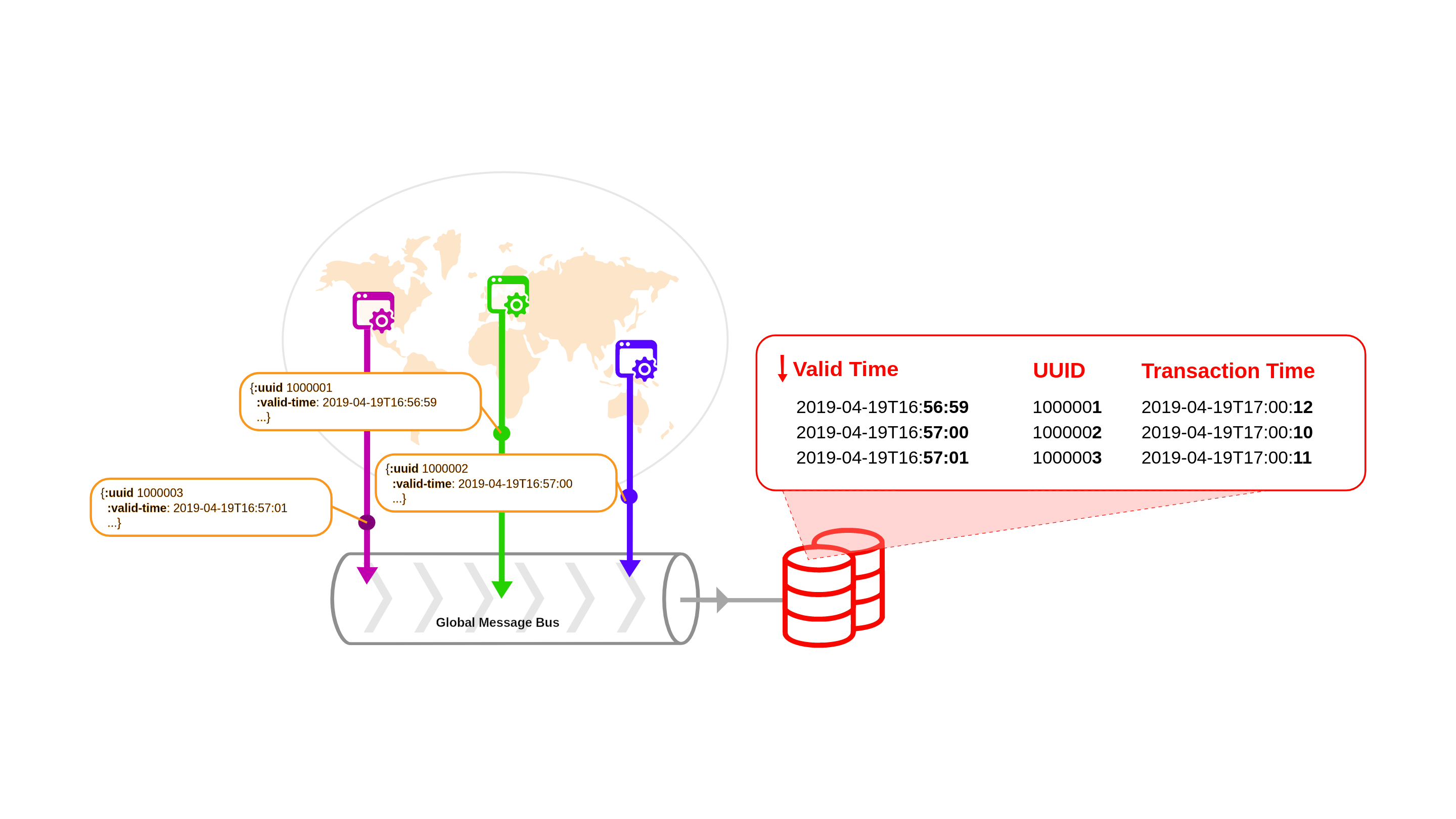
The diagram above shows events from multiple timezones flowing into the same event stream.
To add bitemporality to the events, JUXT used RocksDB which is a robust key-value store capable of handling petabytes of data. They created a key-value pair for ValidTime and TransactionTime (see IndexB in the image below).
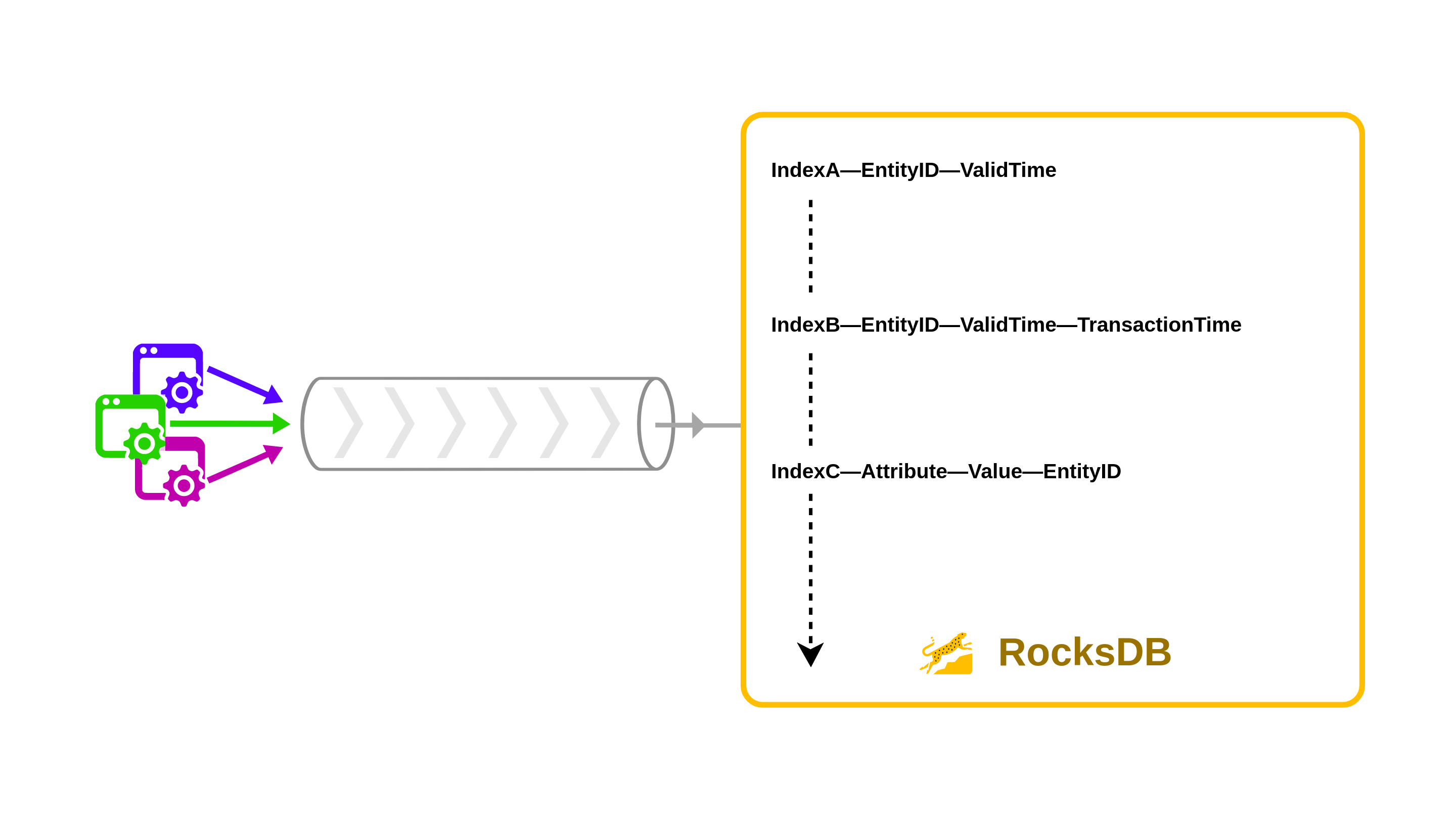
ValidTime is flexible which is why you need TransactionTime to tie it to something that is queryable and IndexC is for joins because otherwise they could not do joins between IndexB & the value they needed to tie to ValidTime and TransactionTime This is a simple way to get bitemporality up and running! They wrap this whole setup with some GraphQL and embedded RocksDB instances on the application node instances, a nice way to get an unbundled database.
Crux
Why Crux?
- Build bitemporality as a feature
- Eviction - a slightly difficult feature to implement, useful for compliance with GDPR, you can keep your transaction topic, but delete messages in the document topic.
- Support Datalog queries
- Provide an API for unbundled database
The operations supported on Crux are
- PUT
- DELETE
- EVICT
- CAS: stands for Compare and Swap and is used to ensure that the data in a document/entity is what you think it is before adding a new version, or else abort the transaction.
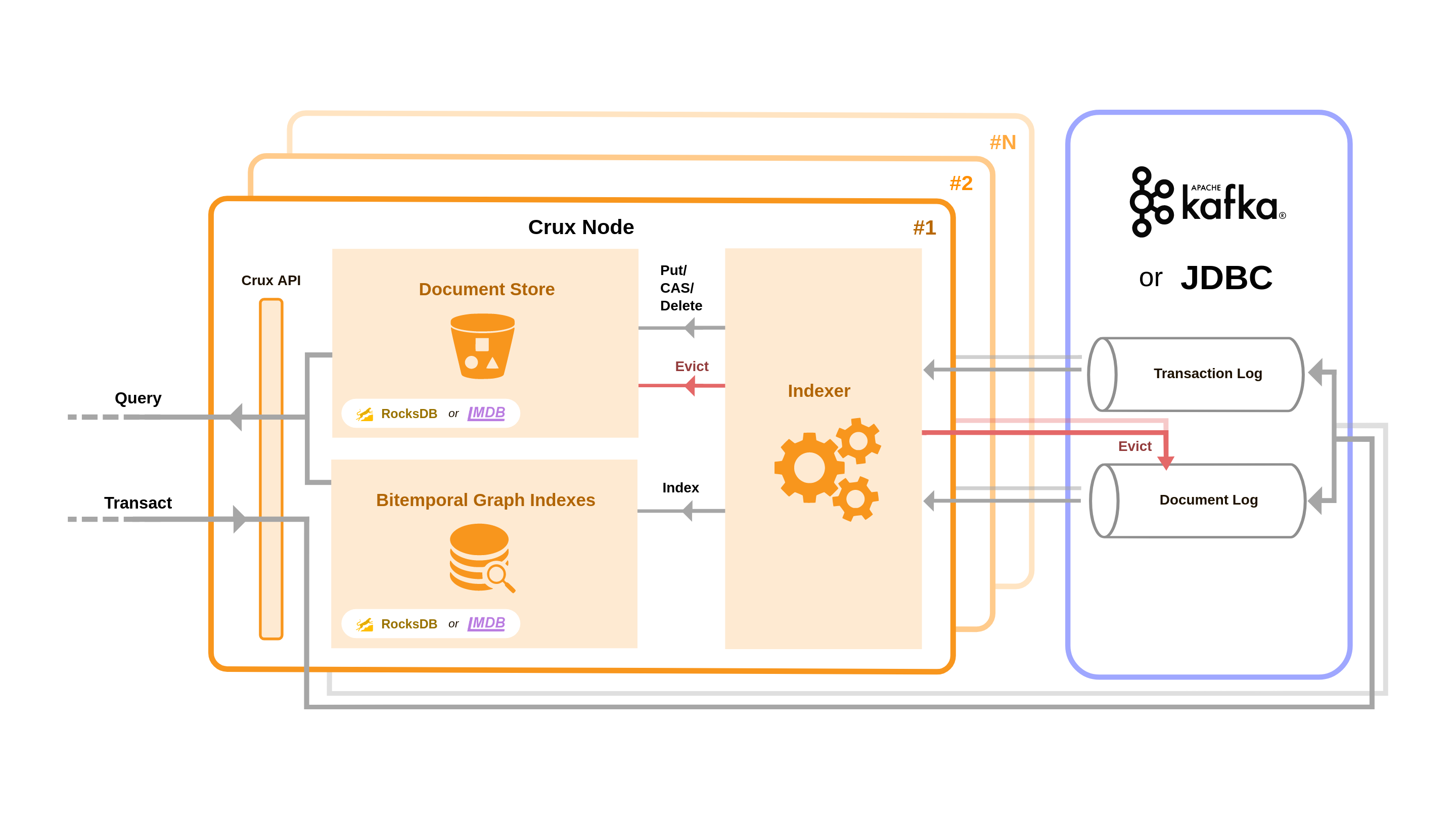
Using a separate topic for documents allows for compaction to remove duplicates since the ID is the hash of the document. Crux nodes ingest data from the event log and index transactions and documents into a key-value store such as RocksDB or LMDB which both serve as local document stores and bitemporal indexes for Crux's graph query. Jeremy mentioned that as an index, LMDB was more performant for queries than RocksDB.
What is Crux simplifying?
Three things mainly:
- Bitemporality
- Eviction: built from the ground up splitting document and transaction logs so that you can delete data for compliance purposes.
- Extensibility
Crux currently supports Java and Clojure APIs.
Jon and Jeremy demonstrated the Crux console as well. It supports both simple and complex queries, joins and quick visualizations.
New features coming soon to Crux
- crux-3df: streaming queries: 3df is a reactive query engine using differential-dataflow
- Kafka Connect
- Benchmarking
- Transaction functions
They are also thinking about usecases around timeseries, JDBC SQL/Calcite queries, adaptive indexing, etc.