Strange Loop 2019 - How to Fix AI: Solutions to ML Bias (And Why They Don't Matter)
Overview
Bias in machine learning is a Problem. This is common knowledge for many of us now, and yet our algorithms continue to operate unfairly in the real world, perpetuating structural inequality along lines of class and color. After all, "better training data" is not so easy to get our hands on, right?
Thanks to [Alla Hoffman}(https://twitter.com/AllaHoffman) for extra notes!
Joyce thanks us all for coming out even though 10.30am can be a bit early.
Joyce gives a quick blurb about herself: She started on ML a few years back. Built ML library in Clojure which is a functional programming language . Worked at Deep Mind , Stanford NLP group and some work on adversarial learning. Joyce then went on to work at Cybot Labs.
While working on ML, the discussion on bias caught Joyce's attention.
Majority of the talk focuses on technical mitigations for bias in data and will be technical. Joyce would be focusing mostly on deep learning. However, using these algorithms is not enough. We are tied into a much bugger problem here.
1. The Problem
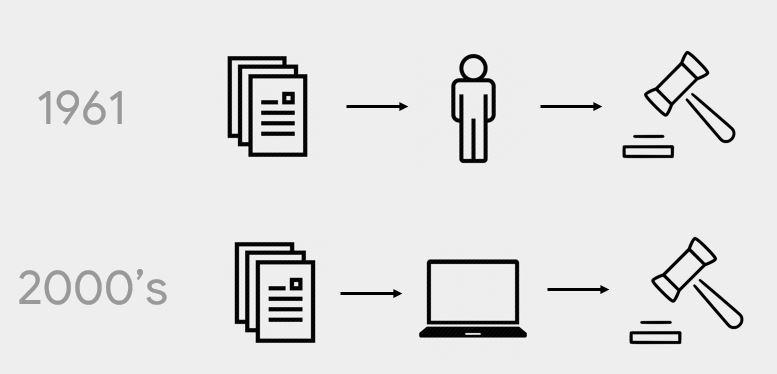
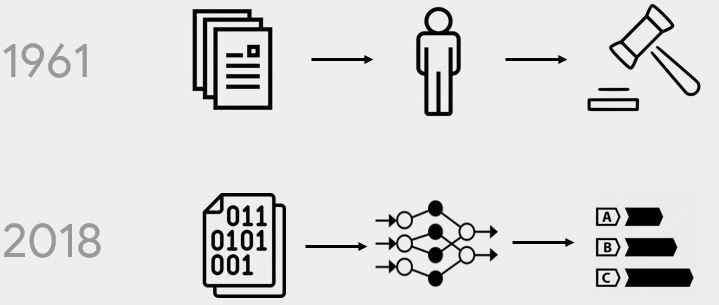
Joyce tells a story from 1961 about a man called Clyde Ross who tried to buy a home in North Lawndale, Chicago. He was a veteran who after WW II had worked for 14 years before he and his wife tried to buy a house. Unfortunately, he gets into a predatory agreement where he pays his mortgage to his seller, but Ross doesn’t get any equity. And if he misses a single payment, he forfeits the property itself. He tried to leave and get new housing but discovered he could not because of redlining. Redlining specifically affected people of color. Joyce tells another story from 2018 where Rachelle Faroud tried to but a house in Western Philadelphia again and again and was denied despite improving her social standing.
In 1968 the Fair Housing Act was passed to protect people from discrimination such as what Clyde Ross went through.
In 1961, people made decisions, in the 2000's computers started making those decisions and in 2018, computers running some form of ML make these decisions.
Research shows that POC are more likely to be denied mortgage loans even after controlling for income, loan amount and neighborhood.
Alogorithms are fundamental building blocks of decision -making in every industry that moves money in the US.
We have algorothmic redlining.
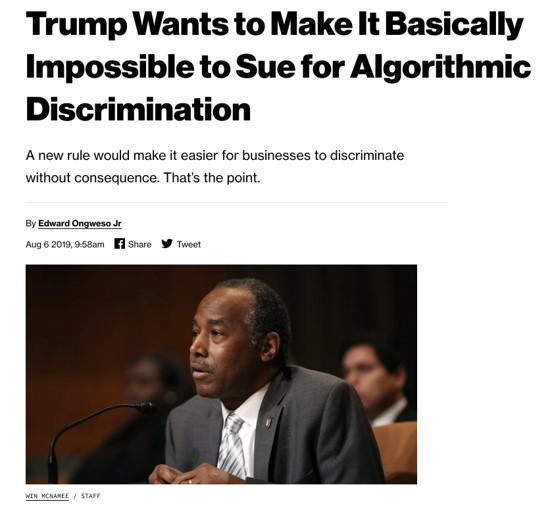
Joyce cites an article that about a proposed housing rule makes it difficult to prevent disparate bias.

2. The Solutions
Knowing that the data is biased, how can we build algorithms that combat this bias, and make accurate predictions in spite of the bias?
2.1 Adversarial de-biasing
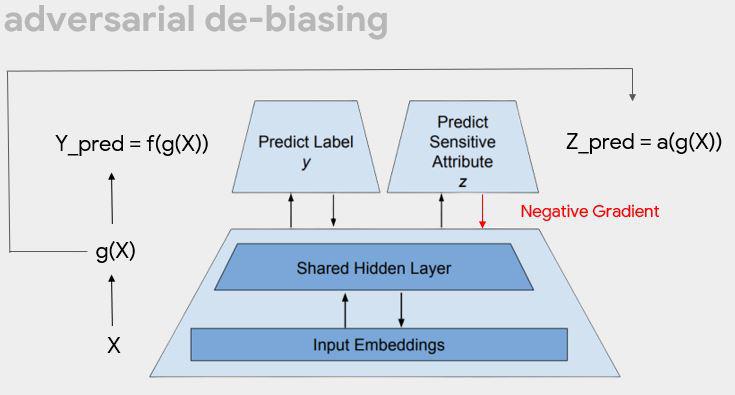
Joyce does a quick recap session on ML. In adversarial learning, let's build a model that predicts the label and the protected attribute. If we can successfully predict what we want but cannot predict this protected attribute, then I have not mistakenly encoded something that reveals the protected attribute. Predict both label and protected attribute (eg race/gender) then send back some negative signal along with the positive if it’s also the protected class.
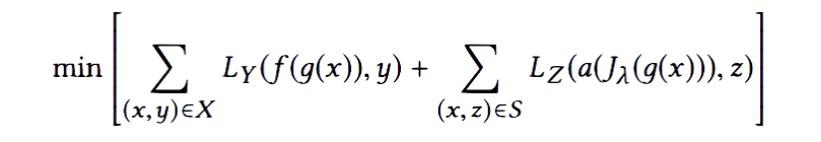
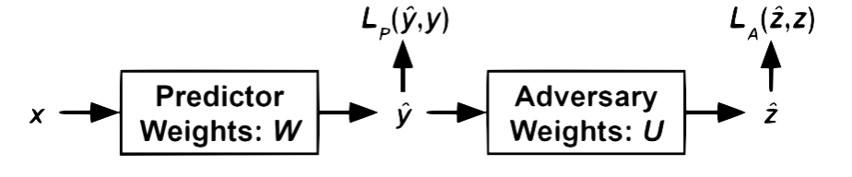
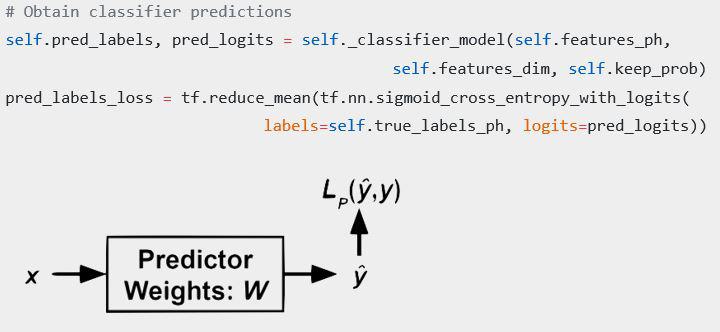

In code, this ends up looking something like this:




The way you make sure the update you are making is maximally useful to classifier without helping the adversary in any way. The thing about AD is you can choose whether you add that separate head. However, you have to specify ahead of time what your protected attribute is. However we may not always know what this attribute is.
2.2 Dynamic upsampling of data
What if you do not know exactly what attribute you want to protect before time?
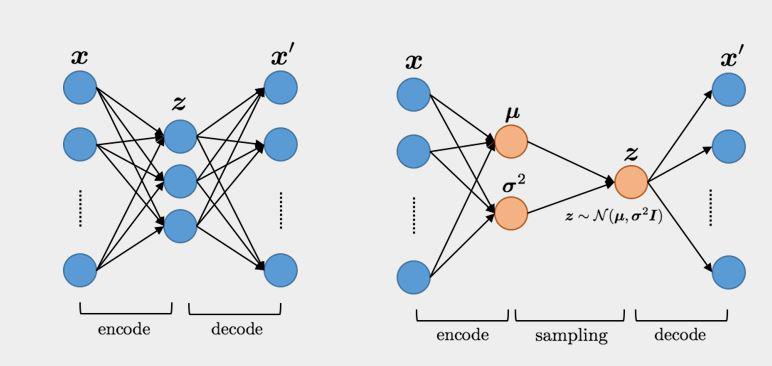
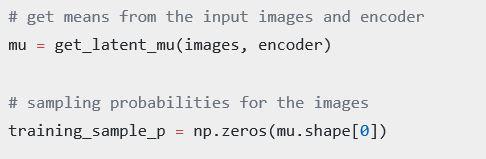
This method variational auto-encoder
An auto-encoder takes in a representation of input and tries to find more useful representation of input in latent space.
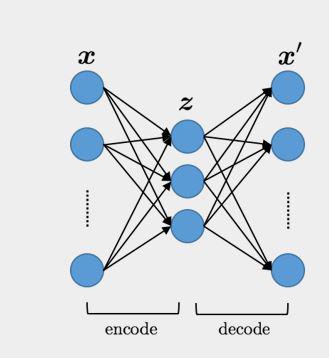
The problem is that sometimes your neural network generates different latent representation of similar inputs. The variational auto-encoder corrects this. We try to make similar inputs are densely clustered in normal Gaussian distributions
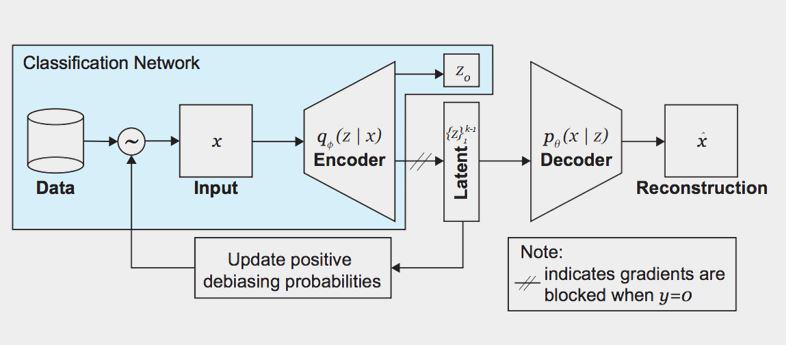
You don’t need to know the exact bias; make sure you see equal representation of different kinds of inputs so it’s well represented (eg detecting women and POC faces)

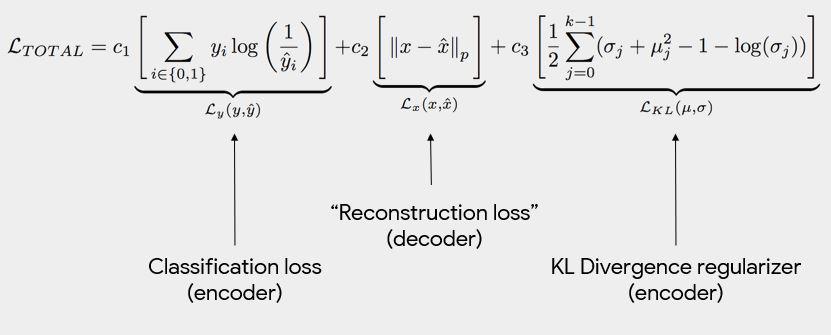
We are trying to have maximize the probability of being able to reconstruct the input from the latent representation. We want to see equal representation of different kinds of inputs so it’s well represented (e.g. detecting women and POC faces)
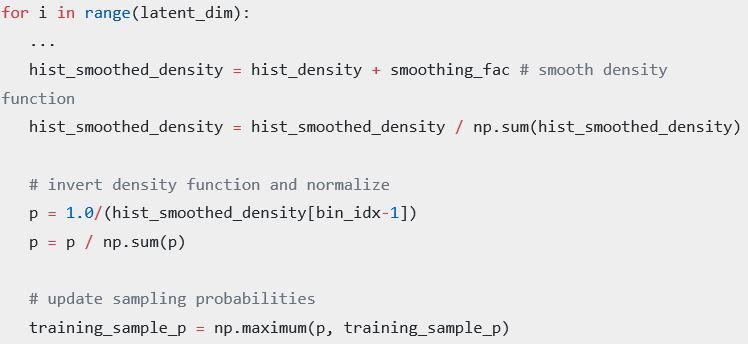
We genarate a histogram of our latent variables.
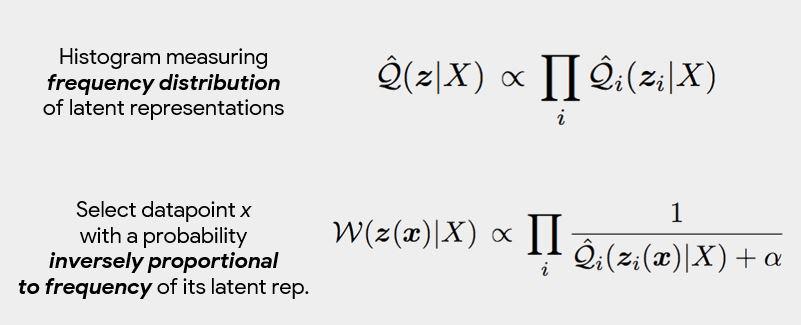
We can upsample data that is unrepresented using the histograms generated for the latent representation
In Code:

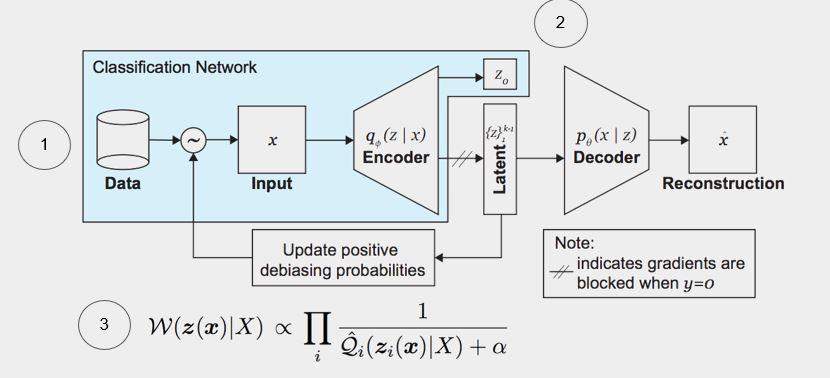
Example from paper using method:

2.3 Distributionally robust optimization
Your model can over time become more biased towards a minority. This is becauseos your model improves with respect to your average which is a representation of your majority. You train looking at samples that have high loss not samples that have low loss. Optimize for the worse off groups.

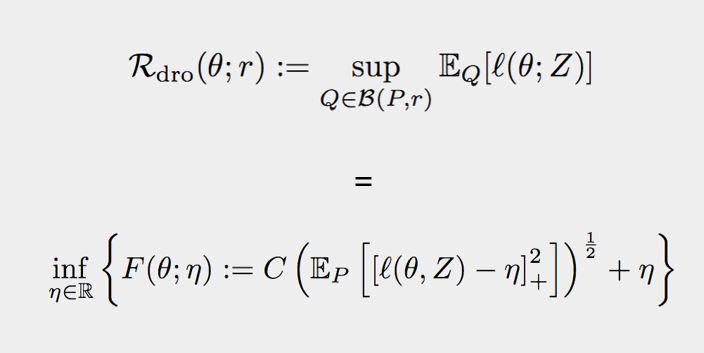

3. The Caveat
In conclusion, Joyce emphasizes:
Just because an algorithm is fair does not mean it is used fairly.