Part 2: How Sourcegraph scales with the Language Server Protocol
Making Code Intelligence “just work”
In my last post, I introduced the Language Server Protocol as the open source protocol that we at Sourcegraph believe will enable a new set of developer tools powered by Code Intelligence. Code Intelligence, if you recall, is just shorthand for
- jump-to-def
- find-references
- symbol-search
- docstring tooltips
- autocomplete
- and more
Or, more pedantically,
Code Intelligence is the set of auto-navigation and auto-generation primitives that use a semantic understanding of code to enable a human programmer to efficiently read and write source code. (See the previous post for a breakdown of this definition.)
The Language Server Protocol was created by Microsoft to make Code Intelligence available for every language in every editor. Because Sourcegraph puts many of the abilities of editor plugins and IDEs into a browser-based app, LSP fits nicely into our technology stack. But Sourcegraph also differs from editors in some critical ways. Our goal is to make Code Intelligence available across many different versions of code (note the different commit hashes in those links), in many different settings both inside and outside your editor, and across a global view of code rather than just the code on your dev machine.
 Global usage examples, one of the advanced Code Intelligence features that only Sourcegraph provides.
Global usage examples, one of the advanced Code Intelligence features that only Sourcegraph provides.
To that end, we need capabilities that the original LSP spec does not describe. Luckily, the original authors of LSP foresaw the need for the unforeseen and made the protocol easy to extend while preserving backwards compatibility.
Though we were driven by our own use case, we also realized that some of the extensions we made to the protocol would be broadly useful to other dev tool creators. Here are two ways in which we extended LSP that we think will be useful to others.
On-demand file fetching decoupled from the filesystem
Traditionally, Code Intelligence has been found only in IDEs and editor plugins. Because editors only deal with code on a developer’s local machine, editor plugins typically interact directly with the filesystem to fetch the file contents necessary to provide abilities like “jump to definition” and “find references.” You’ll notice that many IDEs and plugins take a couple of seconds (sometimes more) to warm up, during which they display a message like “Updating indices.” What’s happening underneath the hood is that they’re re-reading file contents from disk, running them through a compiler-like analysis process, and extracting the information necessary to support Code Intelligence operations.

An excuse to go make yourself some coffee.
It’s bad enough having to wait for your IDE to boot up on the single revision of code checked out on your local machine. But users of Sourcegraph explore code in many different repositories and commits. Because Sourcegraph lets you jump to definitions and references in other repositories, each click could take you to a new codebase and, if we took the naive approach of “Updating indices,” you’d have to wait awhile before you could continue exploring. Friction points like these spell the death of productivity, so we figured out how to do away with “Updating indices” altogether to create a developer user experience that feels instant.
To make this possible, we added an on-demand file fetching extension to LSP. Recall that in LSP, there is a strict separation of editor frontend and language analysis. The language analysis backend is composed of programs called language servers, which expose endpoints like textDocument/definition that map to Code Intelligence abilities like “jump to definition.”
In the original specification, language servers were assumed to have access to the local filesystem, because that’s where the code is for your editor. This doesn't work for Sourcegraph, because we index vast quantities of code across multiple languages — too much to fit on one local disk. Our initial implementation simply used git clone --depth 1 to fetch repositories to language server, but we soon realized this was too slow. Some of the repositories we index (especially the private ones) are massive. It can take twenty seconds or more for the git clone to complete and that doesn't even involve running any code analysis yet.
To make our language servers lightning fast, we had to make files accessible to them file-by-file, as needed.
We extended the original Language Server Protocol to create a way for LSP clients (e.g., editors) to provide file contents and file path structure to language servers such that the language servers never need to access the filesystem directly. The extension consists of 2 simple endpoints:
workspace/filesprovides a list of all file paths relative to the workspace roottextDocument/contentprovides the contents of a file at a specific file path

File fetching in a traditional editor plugin or language server.

File fetching with the LSP files extension. Note the shortened response time.
The file-fetching extension has enabled Sourcegraph to provide capabilities like “jump to definition” and “hover-over docs” within seconds of a user visiting an arbitrary source file at an arbitrary commit in a large repository. The performance is so good that we’ve had many users ask what database we use to store all the data, because they assume we’ve somehow pre-computed the indices. The amazing fact is, we don’t. Everything is done on the fly.
We think incorporating this file-fetching ability into the LSP standard will be useful for editor plugins, too. Many code analysis and compiler APIs already support fetching file contents through an abstract interface rather than directly from the filesystem. They do so both as a performance optimization (hot file contents can be kept in memory) and to support real-time Code Intelligence features like autocomplete, where buffer contents have not yet been written out to disk. The LSP files extension would make it possible to build LSP editor plugins that take advantage of these properties. Perhaps we can look forward to a day in the future where “Updating indices” in editors is a relic of the past.
Cross-repository Code Intelligence
An increasing amount of software relies on code defined outside the main repository, and indeed, the notion of a “main repository” is fading altogether. Whether you’re depending on internal libraries, pulling in open source, or breaking your monolithic application out into separate microservices, code is becoming increasingly distributed across multiple codebases. This presents a challenge for Code-Intelligence-based tools, because now these tools need to be aware of code that might exist outside of your local workspace.
Two of the “superpowers” that Sourcegraph provides are cross-repository jump to definition and global usage examples:
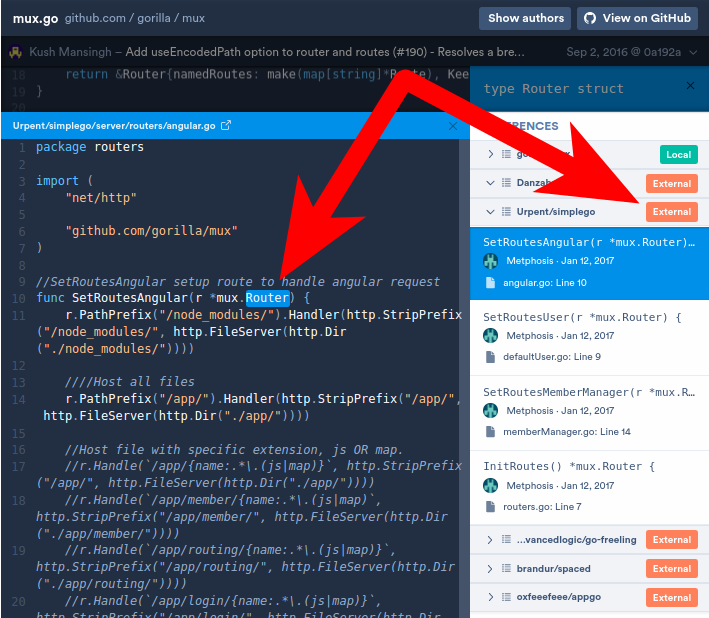
 Cross-repository jump-to-def: “mux.Router” is defined in an external repository.
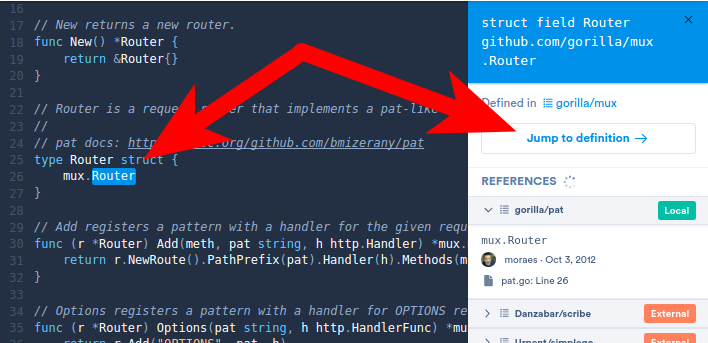
Cross-repository jump-to-def: “mux.Router” is defined in an external repository.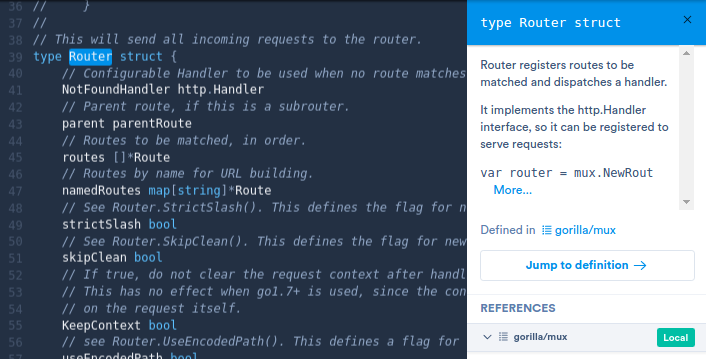 After clicking “Jump to definition,” we’re instantly looking at the definition — defined in a separate repository.
After clicking “Jump to definition,” we’re instantly looking at the definition — defined in a separate repository.
Cross-repository jump to definition lets you jump from the source code of one repository to a definition located in a dependency. On Sourcegraph, this works even if you haven’t vendored your dependencies and, of course, without having to check out any code to your local machine.
Global usage examples is like “find references” across all the code in the world. It lets you see how a function or type is used by others, whether they be fellow teammates or open source developers halfway across the world.
We’ve thought long and hard about how to implement these abilities, and a good part of that thought process was figuring out how to boil them down to a set of primitives that could be provided by language servers. Here’s the set of endpoints we came up with:
- Structured reference lookup (
[workspace/xreferences](https://github.com/sourcegraph/language-server-protocol/blob/master/extension-workspace-references.md#workspacexreferences-extension-to-lsp)) lets you look up the locations of reference in code that match a set of structured criteria (e.g., that reference a certain name defined in a certain package with a certain type). - Structured definition lookup (
[workspace/symbol](https://github.com/sourcegraph/language-server-protocol/blob/master/extension-workspace-references.md#extended-workspace-symbol-request)) lets you look up the location of definitions that match a set of structured criteria (e.g., a definition that has name X and type Y in package Z). - Structured definition descriptors (
[textDocument/xdefinition](https://github.com/sourcegraph/language-server-protocol/blob/master/extension-workspace-references.md#goto-definition-extension-request)) give you a structured property list that describes the definition at a given location. - Package and dependency metadata (
workspace/xpackages) gives you the names and versions of packages defined in a source tree, along with the names and versions of their dependencies.
Cross-repository jump to definition and global usage examples are specific to Sourcegraph’s use case, and they require substantially more infrastructure than these four Code Intelligence primitives. But we believe these primitives are also generally useful to authors of editor plugins and other developer tools. Here are a couple of use cases we find particularly compelling.
Integration with package managers and package repositories
More and more language communities are relying on vibrant open source package ecosystems to share and distribute libraries. A problem that comes with this brave new world, however, is the issue of keeping your dependencies up to date. Wouldn't it be nice if your editor or IDE was aware of the dependencies in your project and could tell you which packages have new versions available for download, or could provide you the set of licenses you’re pulling in through your dependencies? The workspace/xpackages endpoint would make this functionality widely available.
Advanced definition search
Most editors support some sort of text-based symbol searching, but in many cases, you’re looking for something more specific. You might want only to search for functions in some cases, and only types in another. You might want to limit the scope of your search to specific sub-trees on particularly large repositories. Structured symbol search (via the workspace/symbol extension) would allow you to define a specific set of property:value filters to find the definitions that match your criteria.
Tracking a definition over multiple commits
Sometimes code gets moved around. A function might be moved to a different file in a refactoring, but still have the same meaning. If this happens, you have to manually track down the new location of the function, which is pretty annoying. You could build a tool using the textDocument/xdefinition endpoint that matches the definition description across revisions, even if files have changed. You could also use the information to provide better heuristics to git diff.
Advanced reference lookup
Currently, most editors offer a way to find references to a single definition, but sometimes you want to search for references that refer to different definitions that share some properties. For example, you might have functions or methods with duplicate names across different packages. This is fairly common with microservices, where code at API boundaries is increasingly auto-generated from something like Thrift or Protocol Buffers. In such cases, vanilla “find all references” fails. Currently, the best fallback is grep, but grep results often contain too much noise.
Code Intelligence for the future
Both the file-fetching and cross-repository extensions are works in progress. We’re still ironing out the details of the API, and in the meantime have submitted both as proposals to the LSP community for feedback and discussion. The community has been great about providing constructive feedback thus far, and we’re excited to see where the discussion goes.
The extensibility of the Language Server Protocol has made it relatively easy to experiment with new features like those mentioned above without worrying about breaking the backwards compatibility of the dozens of open source language servers and LSP editor plugins currently being developed. LSP is both standardizing a lot of what we’ve come to expect from IDEs and editor plugins and enabling new innovation in Code Intelligence like what you see on Sourcegraph. For these reasons, we think it is an invaluable contribution to the larger software ecosystem. We hope you’ll join us in making it the open standard for Code Intelligence.
In the next post in this series, I’ll dive into implementation details of how we make language servers fast. Stay tuned!
About the author
Beyang Liu is the CTO and co-founder of Sourcegraph. Beyang studied Computer Science at Stanford, where he published research in probabilistic graphical models and computer vision at the Stanford AI Lab. You can chat with Beyang on Twitter @beyang or our community Discord.