My mental model for building and using LLM-based applications
This is an internal document I wrote a month ago for the Sourcegraph team to share my mental model for building and using applications based on an LLM. It mentions Cody, Sourcegraph's AI coding assistant, but the points apply to any application using an LLM. Also, everyone should read Steve Yegge's blog post Cheating Is All You Need.
You need a mental model of LLMs to build or use a LLM-based product
You need to build a mental model of LLMs and Cody to know where Cody works well and where it doesn't, and how best to use it.
Wait…isn't a product supposed to just work? But now we're saying that Cody users need to understand AI concepts and the architecture of our Cody? Yes.
You already have this kind of mental model for Google, but you don't realize it. I remember back in the late 1990s and early 2000s when public libraries in my hometown held adult classes on "How to use Google" that taught how to write search queries for Google. Now Google has gotten smarter in interpreting queries, and using web search engines is so common that it's just assumed everyone knows how to talk to Google, but that wasn't always the case.
LLMs and Cody will get there, but they're very, very new and they're advancing more rapidly than any other technology I've ever seen in my 25 years of being very online. Don't be fooled by other companies' slick AI demos; once you start actually using the product, you'll have some magical experiences and some bad (often bizarre) experiences.
Here's my mental model of LLMs and how their limitations can be overcome.
My mental model: LLMs are booksmart Harvard graduates who can Google anything
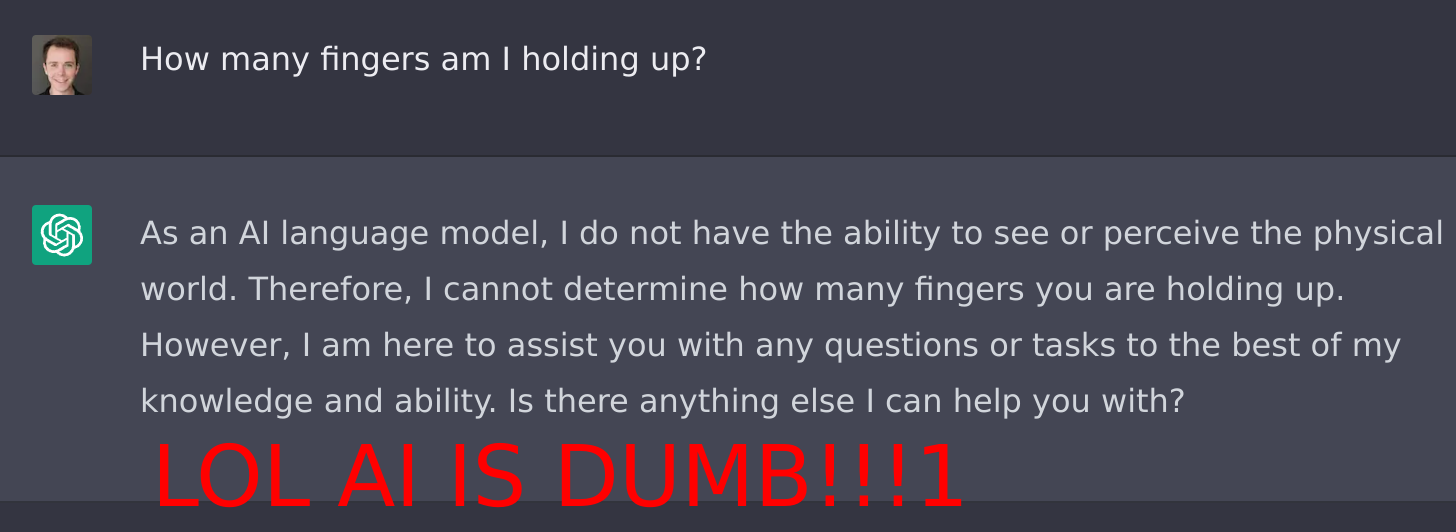
Think of LLMs as booksmart Harvard graduates who can Google anything to answer any question you ask them. There are so many questions they can answer extremely well. But there's no guarantee that they'll get everything right, and they'll often sound confident even when they give a wrong answer.
There's one extremely common kind of question that this Harvard grad definitely can't answer: anything that depends on information it hasn't seen[1]. They even fail at super simple questions that any 3-year-old could answer! They can't answer any of these questions correctly:
- How many fingers am I holding up?
- Am I currently wearing a hat?
- What is the secret formula for Diet Coke?
- What's the summary of the email I just received?
Does that mean they're stupid or useless? No. If they had the right information, they could absolutely answer these questions. But they simply lack this information. Just like this theoretical Harvard student, ChatGPT and Claude fail to answer these questions; try it!
Google also can't answer these questions. You would look pretty dumb if you typed these questions into Google and complained that it couldn't answer them and therefore concluded that Google was stupid.
How to teach an LLM to answer "How many fingers am I holding up?"
But unlike with Google, there's a way to make Harvard grads (and LLMs, in this analogy) able to answer these kinds of questions that depend on information they've never seen before you asked.
How? This is not a trick question. You just need to include the information in your question!
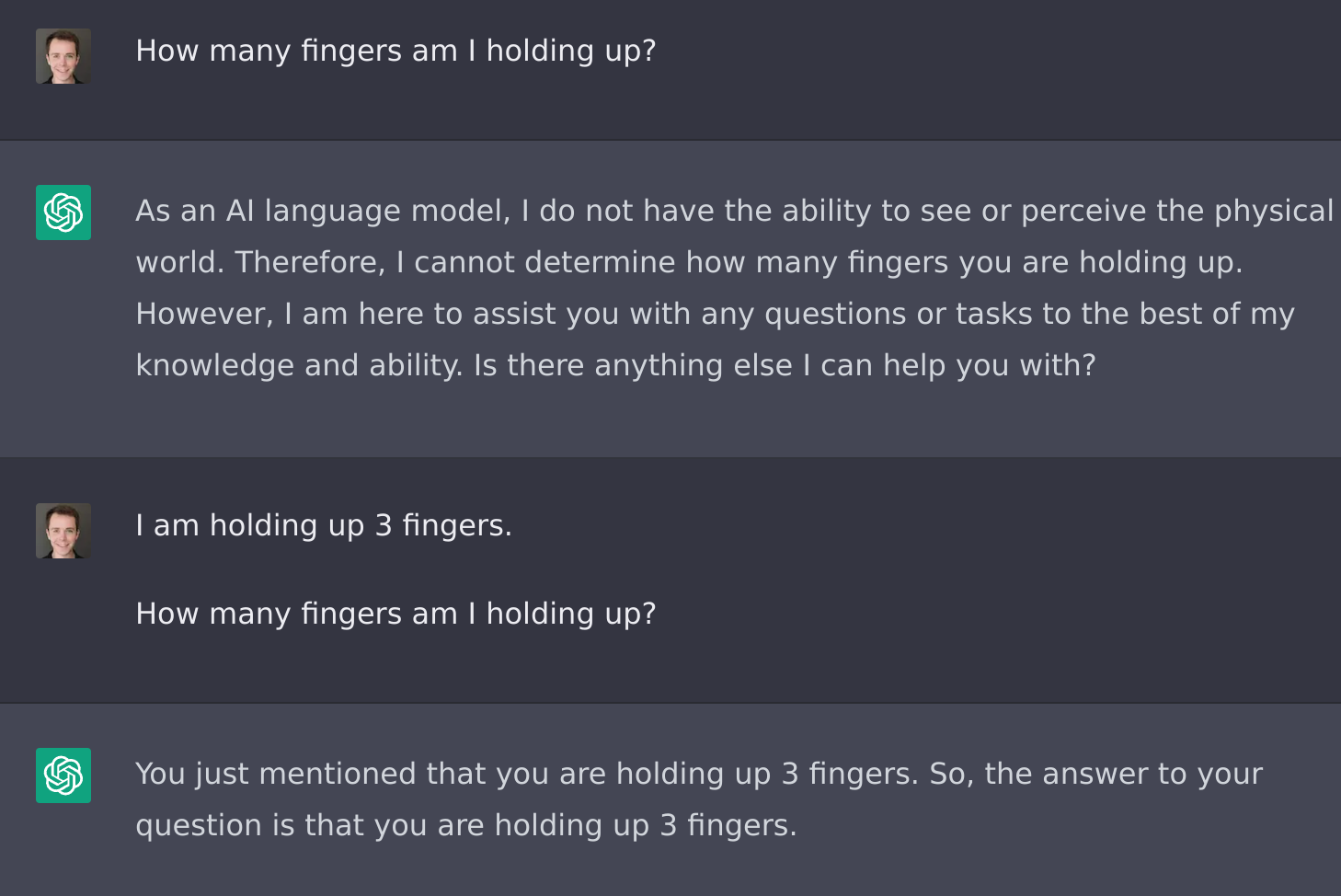
More generally, you could ask it what information it needs to answer your question, and then give it what it asks for.
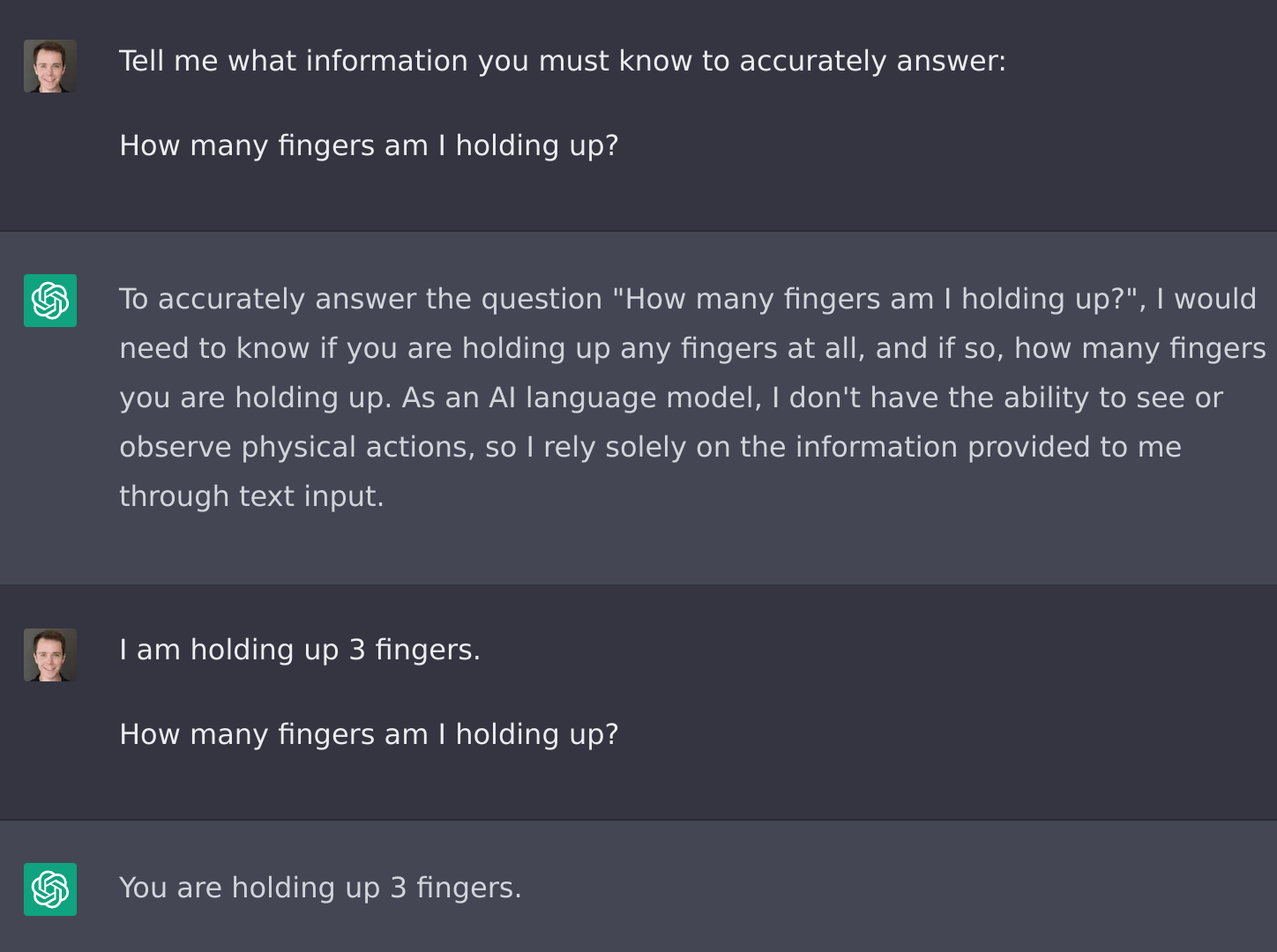
This makes LLMs much more useful. Instead of being limited to the information they were trained on (generally publicly available information on the web), this lets LLMs answer questions that require other kinds of information.
(It's also one of the ways that people fear AI could destroy the world. If I ask the AI what it needs to answer a question, and I give it what it asks for, then I'm following the AI's orders. Today it just asks how many fingers I'm holding up, which is harmless. Tomorrow it asks a human to construct and detonate 100 nuclear weapons…)
LLMs are quite good at coding tasks that people share and discuss publicly
Let's get to talking about LLMs for coding. You know what the LLM has seen a lot of? Code. Especially code that uses open-source libraries in common ways. Also, documentation, StackOverflow discussions, and much more about open-source libraries and popular technologies.
That's why ChatGPT, Copilot, and Claude are good at answering questions about publicly available code and software.
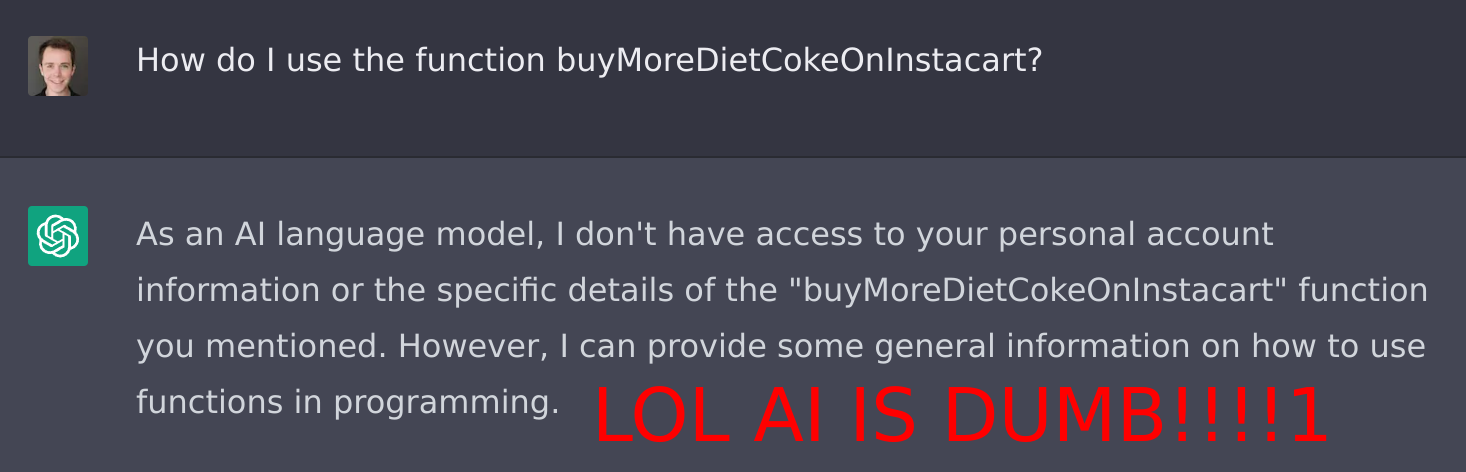
But the LLM has not seen your company's private code, documentation, discussions, etc. ChatGPT can't actually answer any of these questions correctly (and if it does, it's just a lucky guess based on the question and intuition):
- How do I use <name of some internal service>?
- Where is <some internal function> defined?
- How does <some internal system> work?
Again, this doesn't mean ChatGPT is dumb. If you found the best developer in the world, flew them into your office, and offered them $1 billion USD to answer one of those questions, they also couldn't do it. They'd probably say something like: "I have no idea because I'm not familiar with that code." Even if you sweetened the offer to $100 billion USD, they'd say, "I literally can't answer that without being able to read the code."
Hmm…you have an idea. What if you could let them see the code?
Cody "cheats" by rephrasing your question to include your code
That's basically what Cody does: it lets the LLM see the code. It's like letting that best developer in the world read all the relevant code (including your private code, which they haven't seen before) in order to answer your question. Given enough time, they would probably be able to come up with the answer.
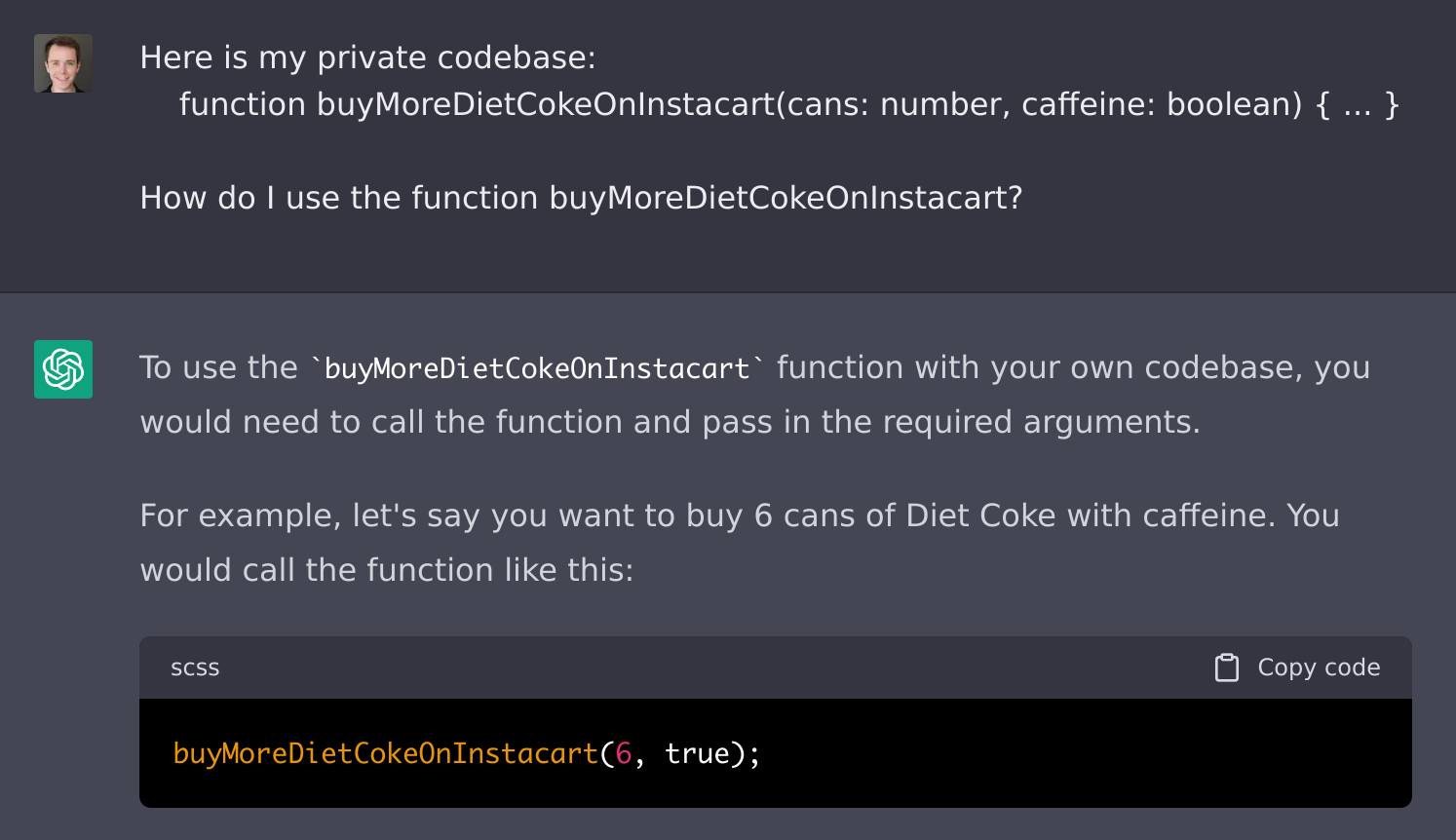
Cody figures out what code to insert above your actual question, to give the LLM context. That's hard to do well! It can't just include every code file, since LLMs limit the length of the questions you can ask it ("prompt" is the technical term). So, it does some smart things to figure out which files to include. There are several techniques for doing this well.
Steve Yegge, our Head of Engineering, calls this "cheating" in his awesome blog post Cheating Is All You Need.
Cody = LLMs + the right context = 🤯
The techniques to make LLMs really good at answering code questions require access to the full codebase and good code search engine. These enhance the context that can be fed to the LLM and therefore enhance the LLM's answer. For example, if your question is about a function called "submitRequest", and that appears 734 times in your codebase:
- You'd need a code search engine that has indexed all 734 places where "submitRequest" is mentioned. (If it only indexed some of them, that would be bad! The answer would be incomplete and wrong.)
- The code search engine needs to quickly and comprehensively return all 734 places.
- The code search engine should be up to date. (You don't want the AI to answer based on yesterday's code!)
- The code search engine should have good ranking. (You'd prefer the AI to rely on high-quality code when coming up with its answer. What does high-quality mean? It's not well defined, but all else being equal, you probably want the AI to be more influenced by recent code written by experts instead of 10-year-old code that nobody uses anymore.)
- The code search engine should…have a lot more code intelligence about the code in all kinds of other smart ways.
- The AI should consult code written by experts in the relevant part of the codebase, not hacky code the CEO wrote in a hackathon. The AI should prefer to consult code owned by your team instead of other teams that might have different practices. (Sounds like…Sourcegraph Own!)
- For queries like "Where is the error in this code?" or "Fix the bug in prod", you need more than just the code. You also need to see logs from the code running in production. If that really good code search engine could go beyond code ownership information and add more kinds of code metadata, devs could ask more kinds of questions.
A really good code search engine? With the best code intelligence that's getting better and more comprehensive all the time? Sourcegraph here, reporting for duty!
There's much more to be said here, but this is why so many people look at Sourcegraph and think we are perfectly positioned to build amazing things using AI + Sourcegraph's code intelligence and search. Everything we've built so far can be put to work feeding context into a smart LLM. (Again, see Steve Yegge's blog post Cheating Is All You Need, and the graphic at the top of our 5.0 announcement blog post.)
{kind=link}
Cody is essentially like a power user of Sourcegraph that can run 1000 searches and read 1000 code files in the blink of an eye, and condense all that information into a single answer (or the right code) for a user within seconds of them starting to use Sourcegraph. (And the same kind of LLM-based application can and will be built on any other kind of good search engine and dataset.)
That's the vision, anyway. It's going to fail in embarrassing ways a million times on the way to realizing that vision. And it might never work as well as we hope. But we're extremely energized by some of the initial results we've seen, and our customers and users are impelling us to pursue this.
Acknowledgments
Thanks to Shawn Wang (swyx), Jonathan Schneider, Micheal Benedict, and John Berryman for reviewing this post.