Exploring data visualization with D3.js and Cody
This article explores data visualizations using D3.js, covering its features, getting started, working principles, and how to create charts with the help of Cody.
James Amoo
This article explores data visualizations using D3.js, covering its features, getting started, working principles, and how to create charts with the help of Cody.
James Amoo

Cody for VS Code v1.14.0 is now available. This update includes expanded input and output context windows, a new chat interface, improved unit tests, and more.
Cody gets even better with multi-repo context support, faster completions, improved commands, and much more. Read on for all the details.
Claude 3, the latest family of LLMs from Anthropic, is now available to all Cody users at no additional cost.

The latest Sourcegraph release includes support for Claude 3 models in Cody Enterprise.

Cody for JetBrains v5.5.2 is now available, including fixes for autocomplete formatting bugs, a new chat export function, and Claude 3 Sonnet for Cody Free users.

Cody for VS Code v1.12.0 is now available. This release brings Claude 3 Sonnet to Cody Free users as the new default model plus several improvements for context handling.

Cody empowers support engineers to unblock themselves and solve complex issues autonomously. By leveraging Cody's capabilities for documentation retrieval, error detection, script writing, and infrastructure explanation.
Learn how to use local LLM models to Chat with Cody without an Internet connection powered by Ollama.

Cody for VS Code v1.10.0 is now available, this release includes support for Claude 3 Haiku, several improvements to doc string generation, and debugging.
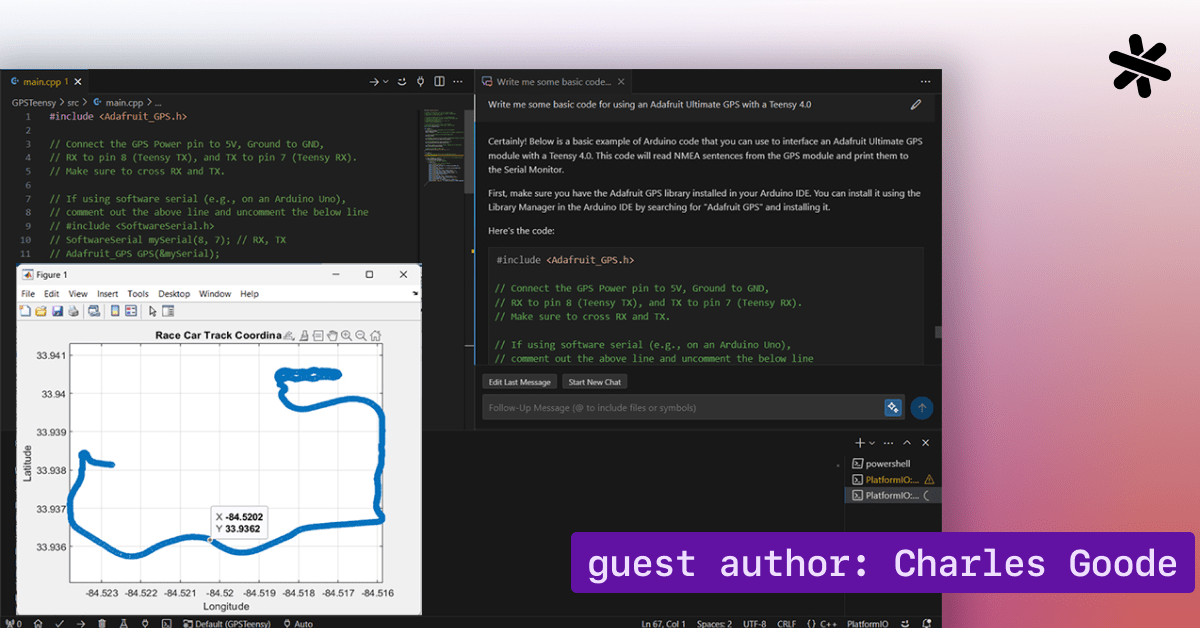
Charles Goode, an electrical engineering student at Kennesaw State University, shares his experience using Cody to rapidly implement a GPS data logging system for the university's Formula SAE racing team, Kennesaw Motorsports.
Charles Goode

The latest release of Sourcegraph's Cody plugin for JetBrains brings exciting new features and improvements. With Claude 3 support, Intelligent file mentioning, better error reporting, and Enhanced remote context for Cody Enterprise users.

Cody for VS Code v1.8.0 is now available and includes support for Claude 3, local Ollama models, @-mentioning line numbers, keybindings for custom commands, and automatic updating of the local search index.

No Internet? No problem. Learn how to use Ollama with Cody for VS Code to get local code completion.

This release includes several keyboard shortcuts, enabling login in VSCodium, reducing autocomplete latency, and fixing issues with chat stealing editor focus and displaying file ranges.
Kalan Chan, Justin Dorfman, Tom Ross, Philipp Spiess, Ado Kukic
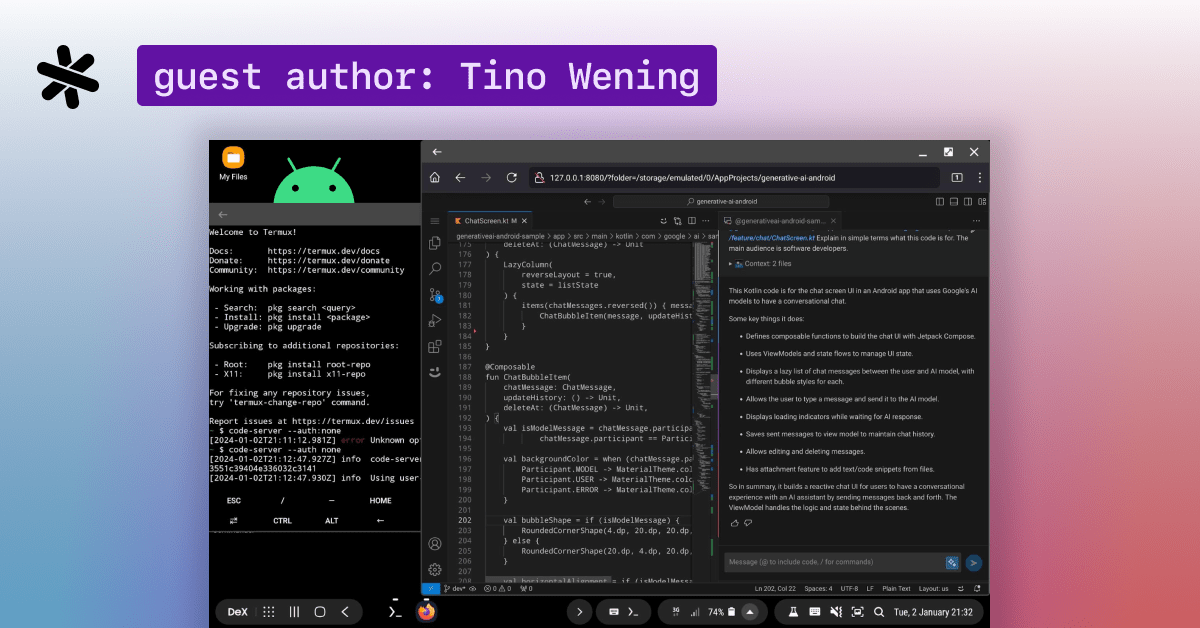
An informal guide for digital nomads, showcasing how Termux and Cody turn your tablet into a beach-friendly coding hub. Ditch the laptop for a lightweight setup with Termux's Linux shell, Visual Studio Code's web interface, and Cody.

We’re proud to announce Cody Enterprise, a significant milestone for Cody that helps bridge the gap between realizing the potential of AI coding assistants and meeting the unique needs of enterprises.
Quinn Slack

Cody gets even better with multi-repo context support, faster completions, improved commands, and much more. Read on for all the details.

Context is key for AI coding assistants. Cody uses several methods of context fetching to provide answers and code relevant to enterprise-scale codebases.
Alex Isken, Corey Hill
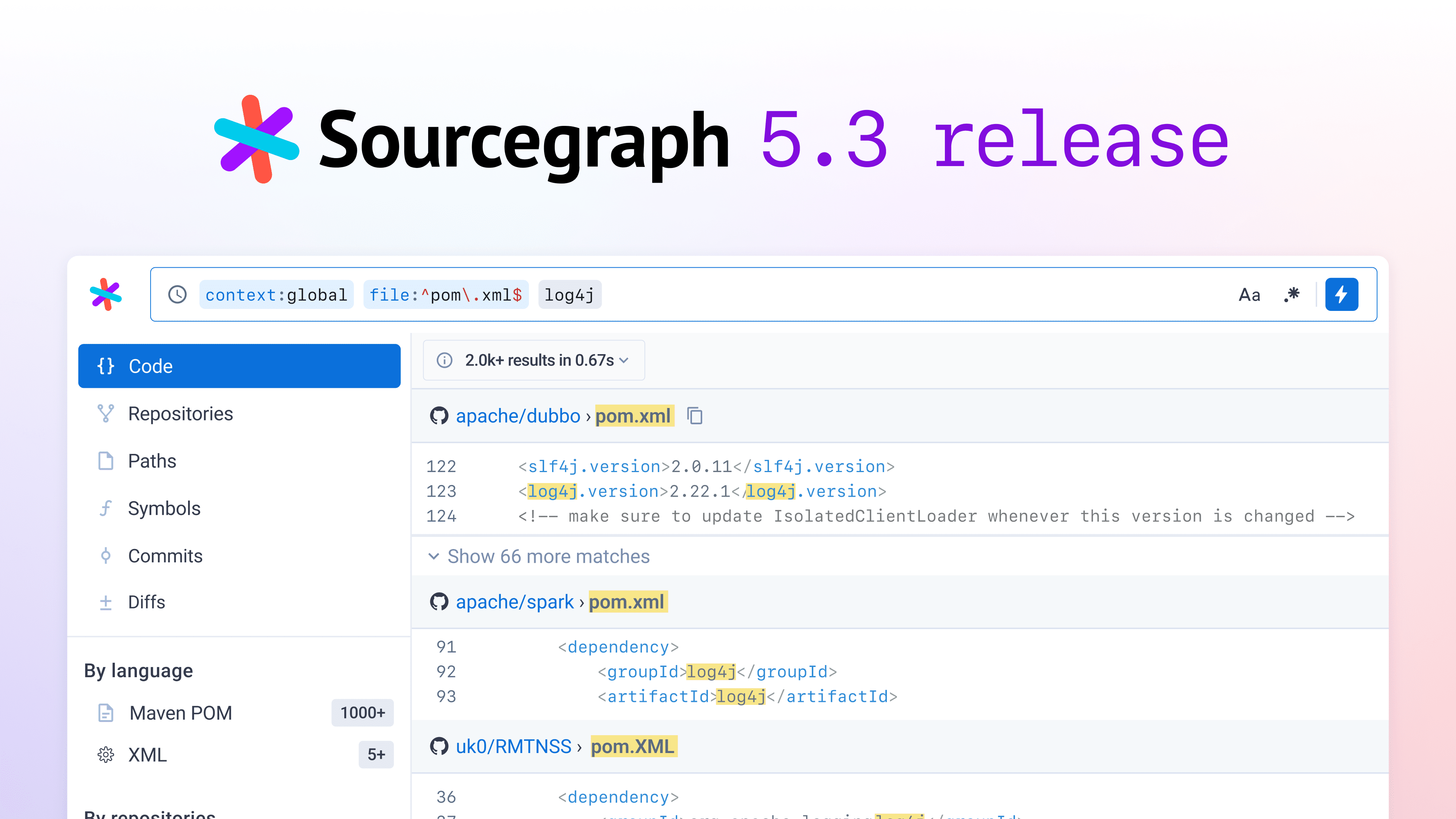
Sourcegraph 5.3 includes security-focused features for Cody along with multi-repo context. Code Search also receives a new search results UX.
Kelvin Yap