Configure precise code navigation for all your repositories in minutes with auto-indexing
María Craig
Code navigation is a crucial component of code search. It allows you to quickly jump to symbol definitions, find references, dependencies, and more, so you can spend less time trying to wrap your head around code and more time writing, testing, and shipping code. Precise code navigation—the most powerful version of code navigation—is very similar to IDE-based navigation, but it also works cross-repository. Imagine clicking “Find references” on a crucial dependency, and finding every reference no matter how many repos depend on it.
Precise code navigation also requires codebases to be indexed. Setting up indexing was previously a manual process done on a per-repository basis. It proved to be a barrier for adoption for some teams, preventing them from seeing the full benefit of code navigation.
Today, we’re releasing auto-indexing in beta for all Sourcegraph customers. Auto-indexing allows customers to set up precise code navigation for any chosen repositories with the click of a button in the Sourcegraph UI. Now, all teams can enjoy precise code navigation with only minutes of setup, and any member of a team can turn it on for their respective repositories.
The history of precise code navigation
Code navigation comes in two common forms: search-based and precise. Search-based code navigation is convenient and available out-of-the-box, but this availability comes at the cost of lower accuracy. Precise code navigation is fast, compiler-accurate, and works cross-repository, matching the precision that developers love about their IDE-based navigation. However, it also requires upfront configuration and compute time to index your code. You can read more about the differences in our SCIP blog post.
Precise code navigation is driven by code graph data. This data is generated by indexing your code (using either LSIF or SCIP format indexers). Historically, indexers were set up to run as part of teams’ CI workflows, and the resulting code graph data was uploaded to Sourcegraph. This could be difficult and time consuming for teams without easy access to edit the CI workflows running on their codebase, which we set out to fix with auto-indexing.
Introducing auto-indexing
Auto-indexing makes it easy to set up repository indexing in minutes and get precise code navigation for your repositories, with no changes to your CI workflow.
It works like this: thanks to our executors service, auto-indexing can be configured to automatically analyze your repository contents. Once auto-indexing policies are configured to fit your needs, repositories will be periodically cloned into an executor sandbox, analyzed, and the resulting index file will be uploaded back to the Sourcegraph instance to power precise code navigation.
Executors provide a sandbox that can run resource-intensive or untrusted tasks on behalf of the Sourcegraph instance. We use them to power features like auto-indexing and running batch changes server-side.
Auto-indexing jobs, in particular, require the invocation of arbitrary and untrusted code to support the resolution of project dependencies. Instead of performing this work within the Sourcegraph instance, where code is available on disk and unprotected internal services are available over the local network, we move untrusted compute into a sandboxed environment. This environment—the executor—has access only to the clone of a single repository on disk (its workspace) and to the public internet.
Self-hosted users interested in auto-indexing can deploy executors by following our deployment guide.
When auto-indexing is enabled, we will also attempt to schedule index jobs for dependencies of the repositories that receive an uploaded index. This helps to ensure that no matter where symbols are defined, you will be able to navigate to its definition and find a relevant set of references as long as your Sourcegraph instance has knowledge of that code. Indexing jobs are scheduled periodically in the background for each repository matching an indexing policy.
Once executors are set up and auto-indexing is enabled, you can configure auto-indexing policies for a specific repository by following these steps.
From the targeted repository’s index page, navigate to code graph settings.
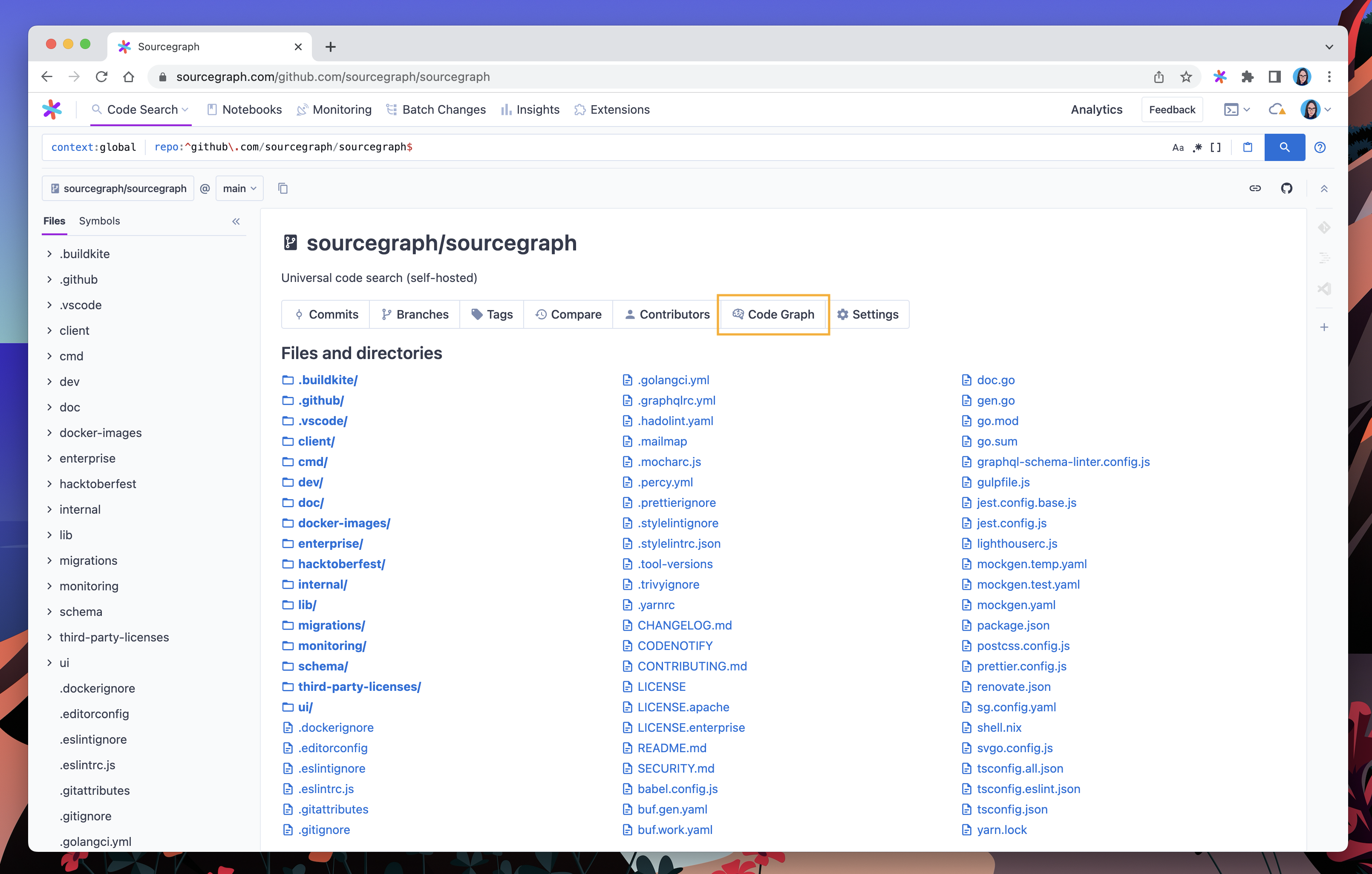
The settings page will show all policies that apply to the given repository, including both repository-specific policies as well as global policies that match the repository (see applying indexing policies globally). You can create your new policy from here.
In this example, we’ll create an indexing policy that applies to all versioned tags in our sourcegraph/sourcegraph repo (those prefixed with v).
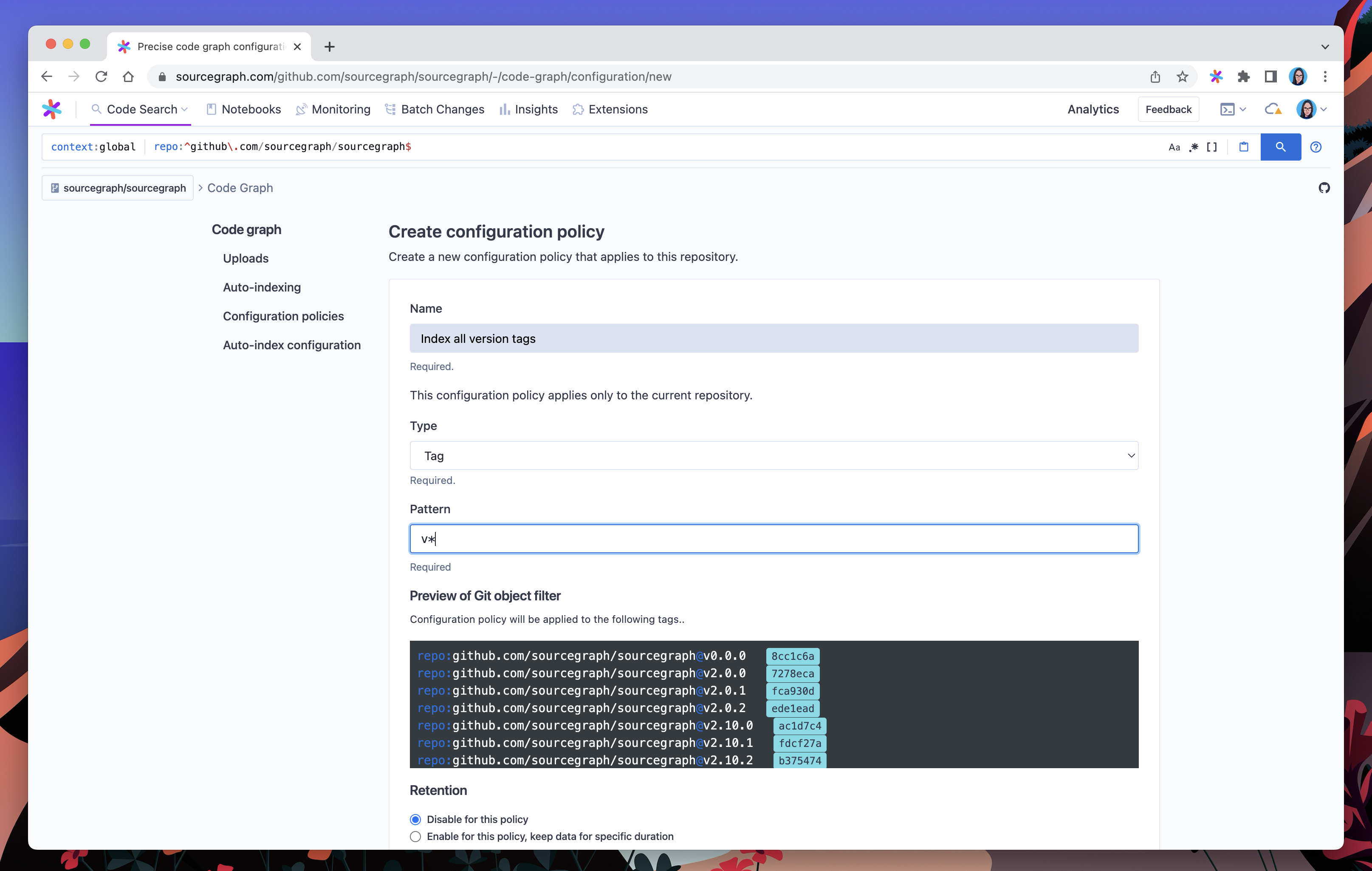
We’ll also set the Retention and Auto-indexing fields to ensure all commits visible from matching tagged commit will be kept indexed (and not removed due to age).
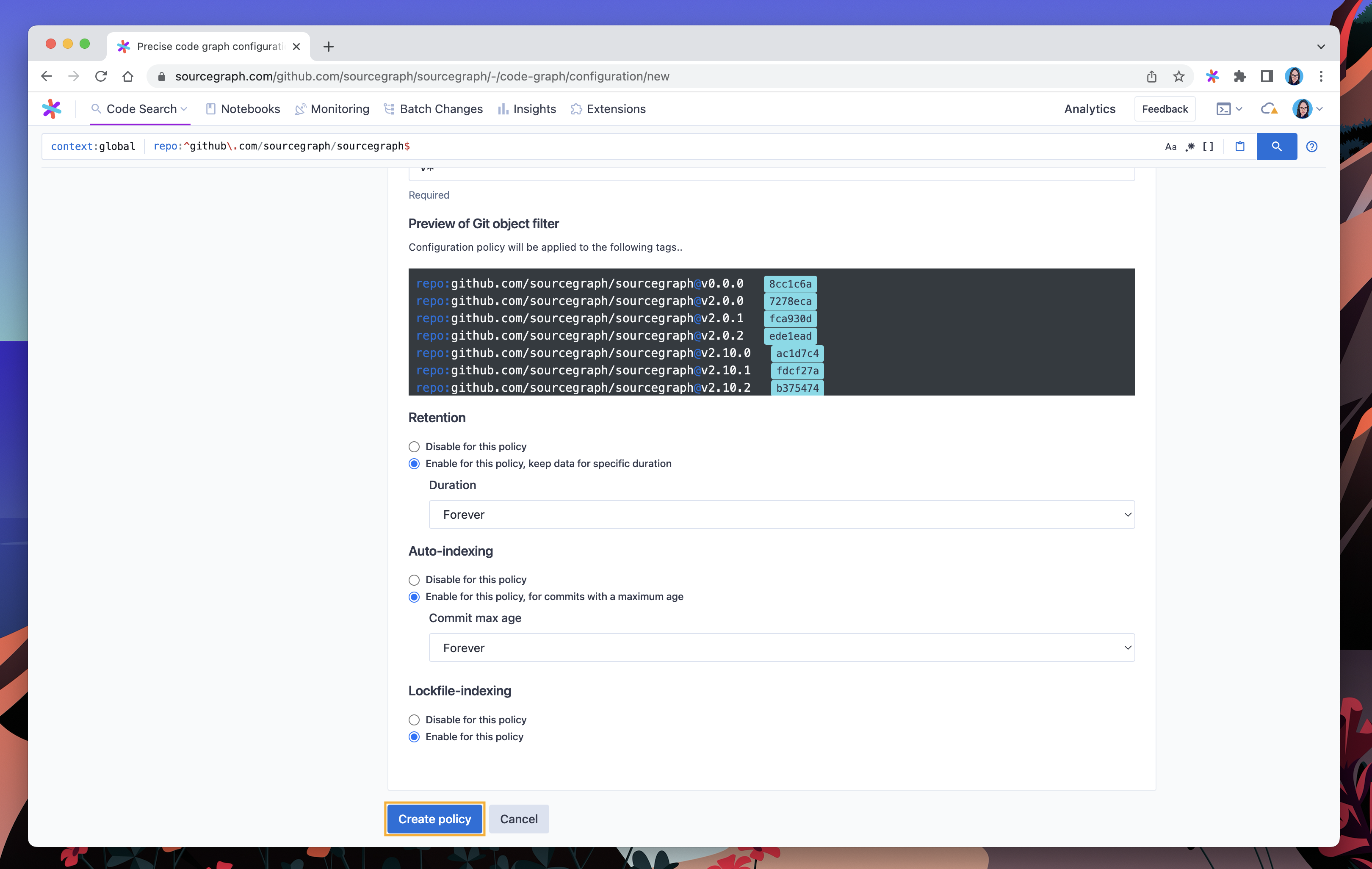
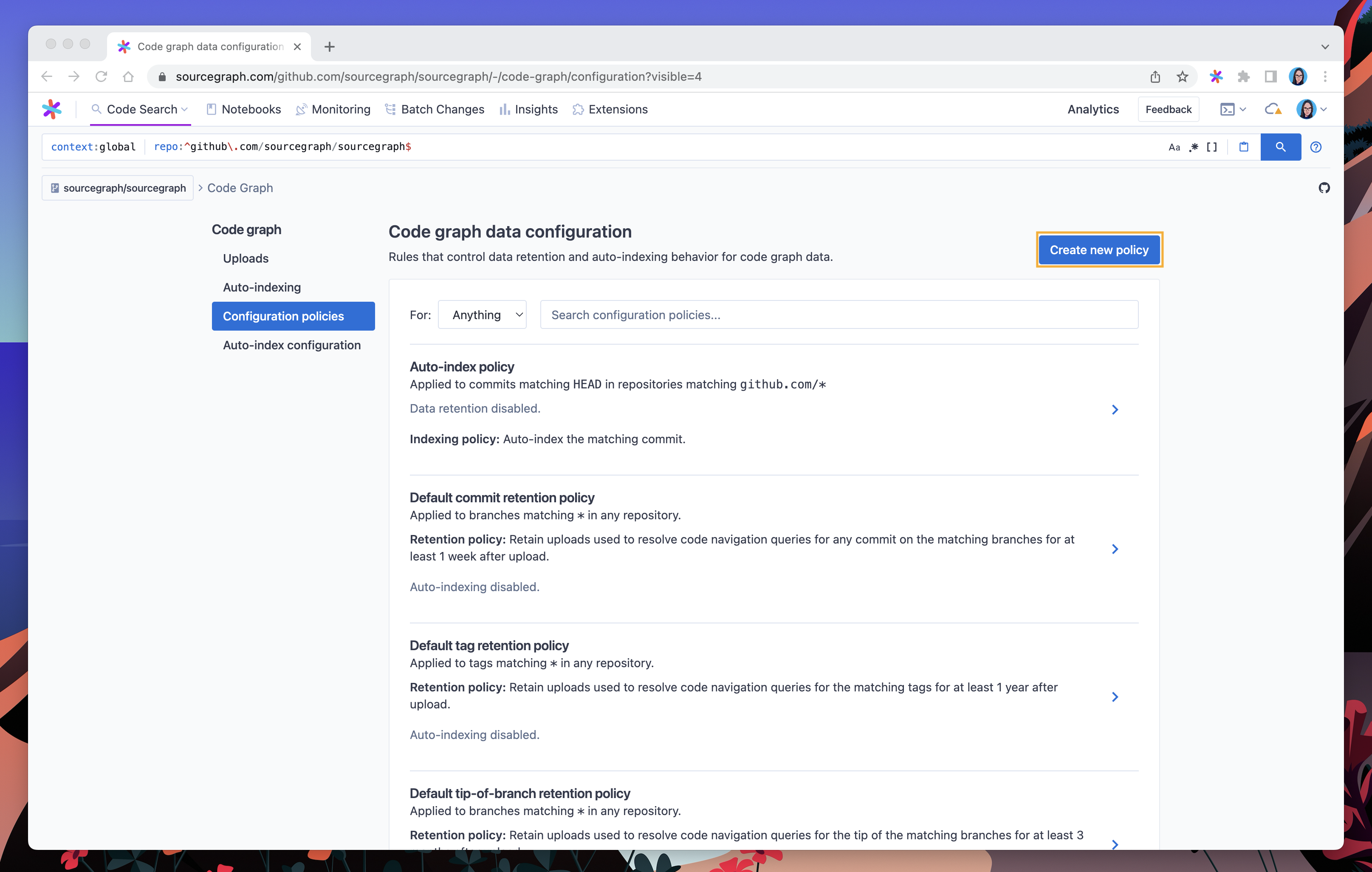
When we’ve finished creating this policy, it will be visible from the Configuration policies view.
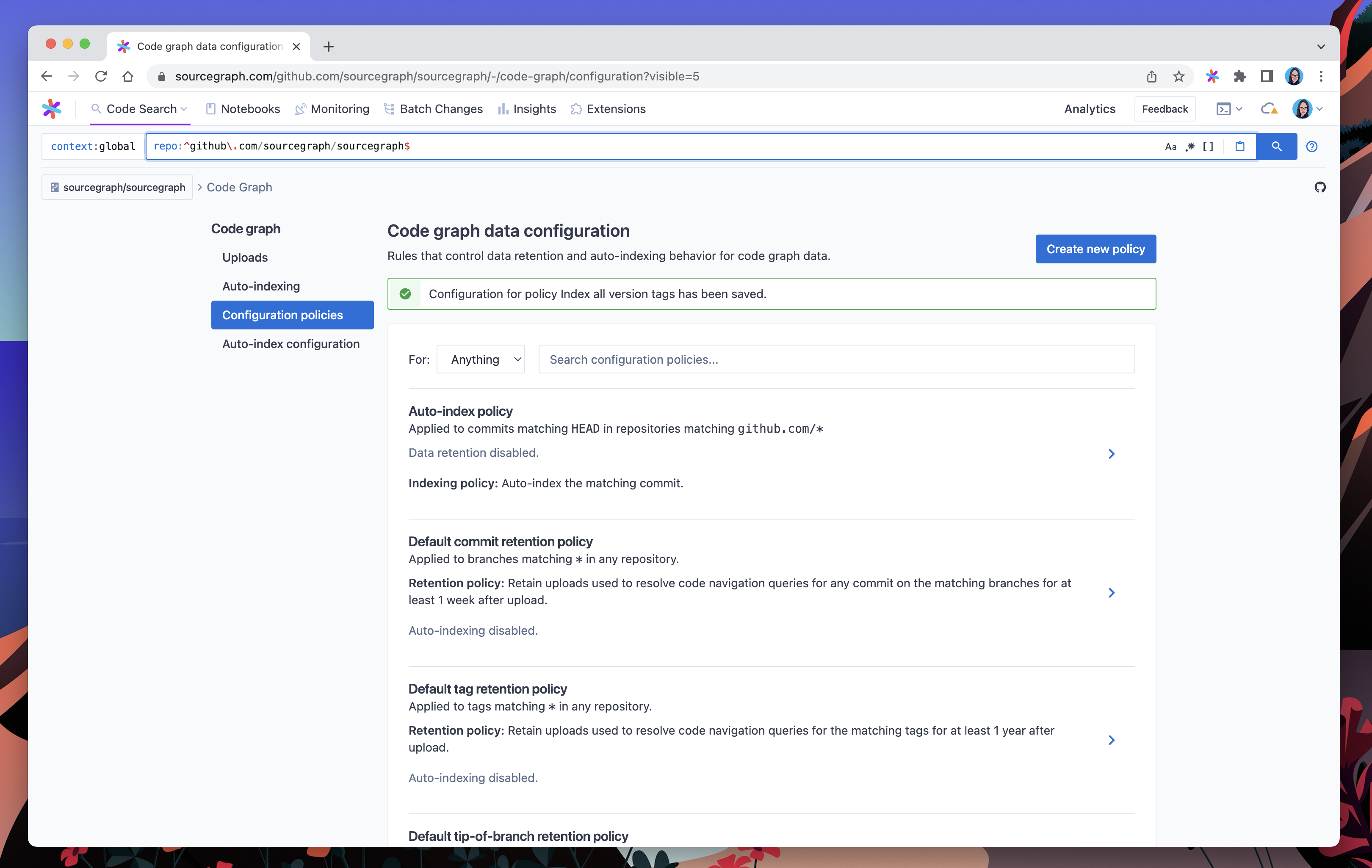
At the moment, auto-indexing is supported for Go, TypeScript, JavaScript and Python. A complete list of auto-indexing support can be found in our docs.
Get started with auto-indexing
Auto-indexing is now available in beta for all Sourcegraph customers, starting at version 3.42. If you’re already using Sourcegraph Self-hosted and on version 3.42 or later, you can read about setting up auto-indexing in the docs.
We also provide experimental support for executors on Sourcegraph Cloud. If you’re a Sourcegraph Cloud customer, you can reach out to your CE to get auto-indexing turned on for your instance.
If you’re not already a Sourcegraph customer, you can get in touch with our team for a demo.